编译原理学习笔记06_antlr初步
antlr是什么
权威解释见官方或wikipedia,我只负责八卦。作者Terence Parr似乎是个有洁癖的人,写了antlr第一个版本之后觉得效率不高又写了v2,因为同样的理由又推倒重来写了v3。尽管以java为主打,但这个antlr非常有野心,Java/C#/Python/Ruby/Scala等语言通吃;由grammar生成lexer和parser使得这玩意儿非常适合教学用,也非常适合菜鸟级程序员提高编写编译器的自信。虽说没有JavaCC这么正统,但是个人觉得非常实用,现在Hibernate framework/Jython/Groovy可都是基于antlr的哦!这哥们还开发了一套template engine,同样是一个妄图大一统文本解析的干活。有了antlr这把锤子他就开始到处乱敲:paper自不用说,然后是《The Definitive ANTLR Reference》、《Language Implementation Patterns》。后者近期被译成中文,号称“屠龙”;虽说的确过誉了,但是不得不承认这本书的确深入浅出。尽管作者一直在自卖自夸antlr和StringTemplate,但是对于java系的人来讲这的确是学习编译原理基础知识的好东西;连Guido大叔和Dalvik设计者Dan Bornstein也对这本书颇有好评。
安装工具
antlr:http://www.antlr.org/download.html
对于我这样的习惯了eclipse的懒人来说antlrworks并不是上上之策,插件才是王道http://antlrv3ide.sourceforge.net/。
该插件特点:
- 新建一般的java project(如果要生成的目标语言是java的话)并convert成antlr即可,之后只需写grammar文件。
- 默认情况下保存每一次grammar文件就会进行自动生成对应的lexer和parser的java文件(默认target language是java)和对应tokens文件;每次打开eclipse时会重新解析一次。
- 似乎生成的lexer和parser并不会添加grammar文件所在package信息(吐槽:这一点和上面一个特点加起来足以让人抓狂!!!)。
- 编辑器的content assit功能和java编辑器的功能有不少出入,括号、引号、缩进等功能做得并不好。
- grammar(g文件)除编辑器的两个tab Interpreter和Railroad view非常棒,一个用于傻瓜式写,一个用于GUI显示,并且可以导出成html。
还可以考虑使用StringTemplate:http://www.stringtemplate.org/download.html
开始使用
以含有加减乘法的计算器且目标语言java为例。
- 在g文件中写出所要定义的grammer(一般是词法和语法的综合)
grammar Expr;
prog : stat+;
stat : expr NEWLINE
| ID '=' expr NEWLINE
| NEWLINE
;
expr: multiExpr (('+'|'-') multiExpr)*
;
multiExpr : atom('*' atom)*
;
atom : INT
| ID
| '(' expr ')'
;
ID : ('a'..'z'|'A'..'Z')+ ;
INT : '0'..'9'+;
NEWLINE : '\r'?'\n';
WS : (' '|'\t'|'\n'|'\r')+{skip();};
- 生成的ExprLexer.java文件中会将'(',')'等涉及判定的字符用新的identifier如T__8等来对应,识别这样的字符的方法形如T__8。新生成的ExprLexer类继承了antlr定义的Lexer类,封装了一些方法。ExprParser继承Parser类,诸如expr等g文件中的左式会有个对应的方法(例如expr())来处理它;为了处理出错和从错误状态恢复,该类还生成了FOLLOW_expr_in_stat34这样的变量并调用了pushFollow()这类方法。
- 这样,从输入流中可以生成lexer对象,将由lexer得到的tokens作为输入就得到一个parser对象;调用顶层的方法就可以完成语法分析了。
public static void main(String[] args) throws IOException, RecognitionException {
// TODO Auto-generated method stub
ANTLRInputStream input = new ANTLRInputStream(System.in);
ExprLexer lexer = new ExprLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
ExprParser parser = new ExprParser(tokens);
parser.prog();
}
- 上述代码对于符合grammar的输入不会有输出,如果需要给出相应的输出的话仍可以在g文件中添加(java)代码。
- 添加包含的package
@header{
import java.util.HashMap;
}
- 添加parser中的成员变量
@members{
/** Map variable name to Integer object holding value */
HashMap memory = new HashMap();
}
- 添加parser中左式处理函数的返回值(前面代码中的方法的返回值都为void),并且在每个生成式上在{}里添加特定的方法。值得注意的是对于诸如INT这样在lexer中得到的Token用的是antlr定义好的Token类的一个对象,包含了getText()方法;故不需要定义INT的text返回值。如下面的一段:
expr returns [int value]
: e=multExpr {$value = $e.value;}
( '+' e=multExpr {$value+=$e.value;}
| '-' e=multExpr {$value-=$e.value;}
)*
;
multExpr returns [int value]
: e = atom {$value=$e.value;}('*' e=atom {$value *= $e.value;})*
atom returns [int value]
: // value of an INT is the int computed from char sequence
INT {$value=Integer.parseInt($INT.text);}
| ID // variable reference
{
// look up value of variable
Integer v = (Integer)memory.get($ID.text);
// if found, set return value else error
if(v!=null) $value = v.intValue();
else System.err.println("undefined variable "+$ID.text);
}
// value of parenthesized expression is just the expr value
| '(' expr ')'{$value=$expr.value;}
;
--------------------------------------------------
参考自《The Definitive ANTLR Reference》,又是一本没付版权费的电子书:(
PS:通过antlr生成的代码,我才知道java对于退出多重循环有个不错的做法,就是在指定的循环前面添加上某个label,然后在要退出的时候加上break label。我们都知道尽管java把goto作为保留字,但是在咱码农是没法用goto的。使用这样break的做法肯定没有C/C++来得凶残;但是无疑很好地避免了goto带来的无结构编程恶习,同时又保留了灵活性(似乎该对D.E.Knuth致敬?)。
用latex的一些总结
用latex时间并不长,不过还是有些想吐槽;班门弄斧,可能就要贻笑大方了。
- 别用latex写中文文档,尤其是含公式不是那么多的情况下。xelatex是latex中文解决方法中比较先进的方法,虽然有xeCJK等包,但是谈起美观来说并不见得咋地。tex本来就不是为非英语母语的人设计的,谁能指望中文中能有和ff中间的横连写相媲美的排版呢?书写文档的效率是一个极大的问题;而更令人发指的就是会有各种过时的package——比如我五月份定制的一个模板现在就没用了(而且是texlive2012和miktex都没有用!)所以现在考虑毕业论文不打算用latex写了(当然如果我不小心用上了luatex之类并感觉中文解决方案良好的话可以另当别论)。
- pdflatex并不是写paper之类文档的首选,对bibtex支持之渣足以让人望而却步;paper之类的东西本身就不需要做得有hyperref这种玩意儿。
- 作为一个既用Linux却又不得不用Windows的用户,装MikTeX或CTeX套件纯粹是找抽的;清一色的texlive才是王道(毕竟这是由TUG亲自维护的)。作为一个码农,用winedt写tex文件不得不说是下下之策;随便找个习惯的editor比如vim/emacs之类的都足了,习惯eclipse的话装个texlipse才是正经。为什么需要用这种渣一样还要注册的winedt呢?数落一下winedt的不是吧:
- 中文编码是永久的伤,乱码一坨一坨的;好些时候得改变编码才行。
- 添加的label更改后必须要刷新之后才能定位到正确的位置,而且对\subsection这样的环境来说如果不显式写出label都不会给个书签之类的东西——这让人如何定位啊!
- 语法高亮的功能就那么几种,而且还经常出错——比如lstlisting中出现$符号居然后面的文字的都变成了math mode的了。
- 假装有了定位起始终结符的功能,可是我发现好几次都把我的数学display环境的范围给搞错了。
- 有几个没多少实质的代码补全功能,比如输入\ begin{itemize}}后其实会把\end{itemize}也给补上且光标定位到这之间;但问题是如果有某个environment之后有参数(比如\begin{multicols}{2})这种功能就全失效了。倒不如texlipse中每次遇到环境时敲回车就补全end来得实在。
- 命令行控制台整个就是一个鸡肋,到现在为止我都不知道在windows下的tex editor为什么需要有这种玩意儿;把原有的控制台功能增强一点不就得了?
- 快捷键异常难用。比如我常用的块注释,竟然需要我同时按ctrl+shift+alt+$\rightarrow$才行;设计UI的人似乎从来没关心过我这种快捷键控的心态!
- 要做成比较花哨的slides的话,beamer绝对不是首选;latex本来就不是设计出来用来放幻灯片的。如果只是因为有一块一块的公式而全用latex写slides的话大部分情况下是自讨苦吃,完全可以对把这些公式单独做成pdf或通用图片式然后插进来(话说这种插入的功能在纯latex编写中也是非常常见的)。对于slides产生的效果来说,beamer本身提供的并不让人满意,ConTeX非常灵活但是对我来说还是太麻烦了;impressive赫赫有名,liyanrui兄的cikala应该很不错(只看过demo但没用过)。但我仍觉得如果是企业里的那种slides的话用latex做实在没必要;学术上除非很formal的东西用latex也是个大坑。
- 涉及到的矢量图如果要求不十分高的情况下用latexdraw之类工具或dot进行转换也可以解决大部分问题了。tikz可算是二维图比较简单的package了,但是用起来还是显得不方便。
- 书写latex的时候,千万需要之前就思考好整体的排版样式;要不然在微调某些environment时会很伤。倒不是说不能,tex的灵活性那是没话说的,latex的高可定制性也比ms word这种非专业排版工具强很多。在编写数学公式时,最好的办法是先手写下来,要不一不小心就写岔了。
- latex的cls/sty定制把内容和显示形式很好地分开了,而开放的格式又让它可以经由其他parser生成各种合适的pdf,dvi格式(或因此生成pdf/ps格式等等);非常符合现代设计思想。但问题是排版是一门细活,的确不是写作本身;所以用latex编写势必会影响行文的思路,尤其是对我这样的新手而言。精工出细活,对于我这种impatient的人来说,尽管仍然对其产生的优美的文档惊羡不已,但是还是感觉不适合;这种感觉就像我现在对C++的感受一样。
- 诡异的是,我想到了一句话:“成功的花,人们只惊羡她现实的明艳;然而当初她的芽儿,浸透了奋斗的泪泉,洒遍了牺牲的血雨”。所以,我依然非常敬佩习惯了用tex写文档的。
码农一年
这几天忙着憋《程序语言理论》的报告,实在不是滋味。九月一号开始,从开始选择材料到最终写稿,花了五天之久;而且只是一片review而已,实在值得反省。
原本只想花三天时间的,结果却拖了两天,渣一样的效率啊!尽管每天为这报告废了不少心思,晚上很少有一点半之前睡的,但是却没有得到应有的效果;令我扼腕N遍。我的时间管理水平真的弱爆了!前些日子看到一篇文章说为什么程序员都不擅长安排时间,看的时候就感觉严重中枪。自从真正自甘堕落成为码农之后,好像就真的没好好的作息过。就拿休息来说,只记得刚读研时还有几分“早睡早起方能养身”的信仰,可惜也就口头说说而已;一周或十天以后,立马reset到混帐状态;再过几天,节操必然掉了一地。就寝时间平均从十二点到现在的一点半,这难道就是蜕变成码农的过程吗?再有,以前可以每天定个计划什么的,然后一件件地解决;后来发现计划从来都和现实完全不搭架——就像笛卡尔说的两个世界彼此不相关联一样;不知道过了多久,连计划这种形式都省了;最后,因为连个形式都没了,计划的内容什么的早就抛之九霄云外。
明天正式开学,今天记下这一年的一些经验教训。
“一屋不扫何以扫天下”,千万不要忽略细节;特别是生活方面的细节。按照道理我还不是太缺德,这些天我一直保持这每天早晨给没洗的衣服换水的习惯;可是从来没有洗过。这个是个老问题,以前也是这样。有时候还总拿出“成大事者不拘小节”聊以自慰,其实这不过是借口罢了。不注意自己的形象,说什么都不对;仪表当然会关系到一天的心情。蝴蝶效应告诉我们,由一发动全身这种匪夷所思的事是很容易发生的。小时候看陈景润的故事,说什么洗衣服也只是在水里蘸一下立马就拿出来;当时对他的窘迫处境同情的同时,还真被他这种所谓的爱惜衣物的精神给打动了。所以以后偷懒怕洗衣服麻烦的时候自然就祭出这位大神来。现在想想,这种狗日的想法实在是东施效颦(其实西施皱个眉头估计并不好看,只是多了个表情让其他看客有了新鲜感)。不过有些故事肯定是润色过了的,很多有避尊者讳的嫌疑(比如帕金森综合征这种玩意儿据说是和某种不良嗜好有关的>_<)。记得小学课本上还有过一个讲卡文迪许拉里邋遢、而只专心做实验的故事,由此看来国内的教育真是奇葩啊;编教材的人大多是流言家吧。读了这么多年的书以后,才发现小时候被灌输的概念大部分是某些人意淫出来的,更可恨的是做了婊子还拉更多的人一起下水。天下大事,必做于细;宁可有“何可一日无此君”的挑剔,也不可以做潇洒的大大咧咧。
作息时间规矩点。这几天每次从实验室回宿舍前都怀疑自己能不能撑过去,说不定在途中就挂了;头脑出奇地不清醒,总有那种喝醉了不听使唤的感觉;骑车都得刻意着不睡着。一想最近又有几起程序员猝死的报导,第二天起床发现自己还活着都庆幸不已。为什么睡这么晚?因为要干活。为什么有活干?一部分是前几天囤积下来的,一部分是因为效率太低拖沓下来的,另一部分是头脑发热想出来的。第一个原因本质上可以归结为后面两个,如果要追溯到前几天的萎靡情况来说的话。第二个原因就复杂了。一方面是当天状态不佳以及意志不坚定导致的,另一方面是本来的制定的任务就是泛泛而谈、不切实际引起的。状态不佳,说到底还是和睡眠不好有关,陷入恶性循环了。意志不坚定哪,原因就多了,不过大部分说白了都是犯贱引起的,但根本原因我到现在还没总结出个所以然来,暂且按下不表;只是用什么“每个月都有那么几天”来搪塞实在是吊丝所为。第三个原因是下一个话题,现在先说服以后又想晚睡的自己为什么晚睡是可耻的:说白了我骨子里深受孔子提倡的不白天睡觉的观点的影响,所以每次起晚了都感觉对不起谁似的。晚睡晚起并不是十恶不赦的罪(连违法都不是>o<),只要睡眠时间充足就够了;可是晚起导致的罪恶感反而影响了下次晚睡的心情继而影响了睡眠的质量,这却是大大的不该。另一方面,大部分人的日程安排都是以白天为主的,鹤立鸡群要别人迁就你显然不现实,那就只能从了大流(除非是老毛这种专门倒时差的人。可是我是那种大神吗?);在这种情况下,只好用着不清醒的头脑去应付,继而罪恶感有加强了,周而复始堕入阿鼻地狱不可脱身。。。不过这大概只是对晚睡不习惯的原因——毕竟大部分人从小都是从不晚睡做起的,偶然晚睡自然迷失了:什么时候起呢?什么时候吃早饭呢?什么时候干活呢?原本养成的习惯现在居然要经过头脑的几番思考之后才能弄清楚,着实不是一件省心的事。再有从进化论及生理角度来讲,晚睡的确不利于健康——陶指导不也是没有调理好作息时间吗?当然,作为一个需要动脑筋的人来说,晚睡最大的损失莫过于头脑不清醒了。这几天的睡眠不好,我感觉在读资料的时候总不停地产生各种没有意义的怀疑;作为一个平时就喜欢瞎想的人,这无疑是雪上加霜。后果是,缺少了很多deep thought而只是停留在表面作者的观点上;子曾曰过:“举一隅不以三隅反,则不复也”,我大概直接可以让子“余欲无言”了。而在头脑不清醒的情况下写出的代码,bug多多啊。那种传说中的“知道洛杉矶每天凌晨4点的样子”的程序员,真的不是我这种人可以想象的。
要有计划。“凡事预则立,不预则废”。即使没有完成计划的内容,也总比连计划的形式都没有好。形式主义虽不可取,鉴于但是我至少还是一个没有完全没有去棱角化的人,对于这种形式和内容不一致的行为我还是有警觉的。所以,在看到目标太高的时候(大部分是这样),我还是会去思考如何调整的;尽管这耗时耗力,但至少没有偏离主题,而且今后在这个上面栽跟头的机会就少了。然而事实情况是我越来越懒得明确计划了,或者说清晰化目标。当然在没有亲自实践前所立的计划一般都是非常模糊的,尤其是没有多少经验的情况下;完成任务的同时就是一步步细化并调整自己目标的时候。但这不代表开始的计划可以设定得也那样扑朔迷离——那只会培养自己优柔寡断的能力。为什么总有人说程序员不会掌握时间?我觉得那是因为码农这个职业完全是一种反一切计划的勾当!有太多的未知需要去探索,你要了解计算机体系结构,要了解多种编程语言,要理解各种设计模式,要能做web应用又要懂移动互联网,要轻松上手各种库,要做各种配置(当然这还都只是工业应用上面的)……让人的感觉是“一入码门深似海”。而事实是这到处都是坑啊,你丫的想填根本是不可能的!愚公移山的故事固然很振奋人心,但这不过是用来骗小孩子的;什么“子子孙孙无穷尽也,而山不加增”——整个就是可笑的朴素唯物主义嘛?没文化,真可怕;再一次有撕中学语文教材的冲动(古人没有科学知识也就罢了,现在都什么时候啦;难道这教材能入选只是因为某领导人碰巧写了一篇和这相关的著作吗)。Knuth老先生号称CS泰斗,为了写SAT这一个方面也只好读了一整年的paper;并且在写完第三卷TAOCP后才发现他想把仅仅计算机科学的内容全部囊括的幻想造成泡影了。所以,程序员们不出意外的话一直都是noob,未知的东西远远出乎想象。这种不确定性导致,往往我们自以为简单的东西实现起来需要很久很久;当然也可能因为找到了某个lib或某人的source code原本苦苦思索的事情一下子就搞定了;再加上有时候需求的突发变更,程序员想定个实际的计划的难度可想而知。细细分析一下,导致我现在不立计划的一个很大的原因就在于在过去的一年当中我很大程度上都是从无到有地在学,一直是以菜鸟的身份存在着的(当然会有触类旁通的时候,但那只是起到帮助入门的作用)。不过我现在可以自信地说我不再是那种屁事都不懂都不精通的人了,所以重新养成立计划的好习惯吧。写计划是有讲究的,我以前订了不少好高骛远的计划,还有不少看似完美但确实不够科学的计划。其实理性地思考一下,写计划其实很容易;写之前分个优先级,列出前面的;给个时间段,OK。当然必须还得看一下,这样的计划自己能不能扛得住——这就得靠经验了。最近得到的一个结论就是,一定要几件事情一起做。比如我这几天就妄想一直看paper然后写,结果中途微博啊、豆瓣啊、知乎啊、twitter啊、人人啊什么的稍微不耐烦就上了;最终希望自然是义不容辞地破灭了。
编译原理学习笔记05_解析树和AST
参考自《Language Implementation Patterns》第4章。
----------------------------------------------
识别语句时,需要关心元素的顺序,同时也要考虑元素之间的关系(嵌套);用树状结构较好(同时可参考xml及lisp,话说含嵌套的list应该就可以理解为tree了吧);parse在进行自顶向下解析的时候一般是可以描绘出parse tree的(它恰好是parse的执行轨迹)。比如在解析x=0;时是通过这样的规则的:
statement:assignment
|...
;
assignment:ID '=' expr
|...
;
expr:...
;
用(已经简化了的)解析树表示就是:
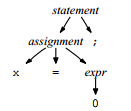
但是这其中涉及到的内部节点其实只在解析过程中有用,那些assignment这类的都只是中间表达形式,真正有用的是叶子节点(terminal);同时这样的树遍历起来也不方便。所以只要能解析(在这里就是抽象地表达赋值语句)并构建其他数据结构(可能下面的阶段会用到),用AST就行了。
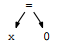
在AST中,操作符的优先级越高,位置越低;这和写规则的时候用到的中间变量的层次是一样的。比如含有+,-,*,/的单数字文法:
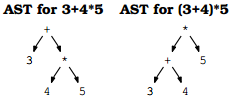
expr:expr+term|expr-term|term; term:term*factor|term/factor|factor; factor:digit|(expr); digit:[0-9];
前序表达式可以唯一确定树的形式,这可以作为树的文本表示形式(又是lisp)。
对于不含可执行语句的语句,可定义伪操作(如graphivz);对输入中没有作为root节点的token时可定义虚token(如c中的声明)。
理论上说AST节点其实只要一种数据结构就OK了,这样设计的AST结构成为同型AST。下面是java的一个实现。
public class AST {
Token token;
List<AST> children;
public AST(Token token) {
this.token = token;
}
public void addChild(AST t) {
if (children == null)
children = new ArrayList<AST>();
children.add(t);
}
...
}
这里用于区分不同类型语句的其实是靠token的类型来完成的,就像这样tree.token.getType()。这样的设计渣的地方显而易见。首先类型token的属性而不是节点的属性,带来的性能上的问题很大;很明显一般来说这样的代码是需要重构的。其次如果要添加额外信息的话不管三七二十一所有节点都得加上,代价太大。虽然simple&stupid,但对于OO思想占主流的时代这样的数据结构显然不能令人满意啊(这不gcc都用C++写了)。因此有了异型AST(又分为规范子节点和不规则子节点两种),以后详述。
编译原理学习笔记04_LL及谓词解析
从现在起正式把《编程语言设计模式》(中文版和英文电子版)加为参考书目。
-----------------------------------------------------
对于一个parser,规范的命名是LL(k),LR(k)之类。LL(k)的含义:第一个L只按从左到有顺序解析输入内容,第二个L表示自顶向下解析时按照从左到右顺序遍历子节点,k表示forward的token为k个。而LL(k)中的r表示的是自底向上解析时按照从右向左推导(从左向右规约)。
LL分析的时候先看到的是产生式左值,然后确定其是由什么右值构成的;于是要做的事就是迭代地匹配产生式,这涉及到了不断地猜测、回溯,通常将A的产生式分为first(A)和follow(A)(和lisp中的car/cdr看起来有些像哈>o<)。这里的“顶”应该是从语法树上看的。LR正好相反,是从产生式的右值开始分析的,开始拿到的是推导式右值中的一个文法(grammar)符号;也可以说是从语法树的叶子节点开始分析。
上下文无关文法(context free grammar)是指没有二义性的文法。一个具有二义性的语法可以参照C++:
T(a)
在只知道T和a是token的情况下,它可能指下面几种情况(或其中一部分):
- 函数声明,如int foo(int);
- 对象初始化,如Fraction f(42);
- 函数调用,如bar(-67);
- 强制类型转换,如float(11);
当然在C++手册中规定遇到这种情况声明(a)比表达式(b)(c)(d)优先级较高,所以在构造解析规则的时候通常隐含(用了if-else等分支结构)对解析选项进行了排序,例如:
stat:(declaration)=>declaration
|expression
;
也就是说只要看起来像声明了,就认为是声明;确定不是声明那种货色的了,才考虑它匹配表达式。但问题在于仍然没有办法区分(b)(c)(d)的情况。如果用LL(k)的话,因为在对象初始化前还有一个token(如Fraction),是可以区分(b)和(c)(d)。然而,仅凭这些还是无法区分(c)(d)。事实上这两者的CFG是一样的:
expr:INTEGER
|ID '(' expr ')'//bar(-67)
|ID '(' expr ')'//float(11);
;
这时就需要采用语义信息了,通常LL(k)是采用形如这样的谓词判断:
void expr() {
if ( LA(1)==INTEGER) match(INTEGER);
else if ( LA(1)==ID && isFunction(LT(1).text) ) «match-function-call »
else if ( LA(1)==ID && isType(LT(1).text) ) «match-typecast »
else «error »
}
在编写解析不同同种语言的解析器是也会用到谓词逻辑;比如gcc的那100+个坑爹的选项,比如java的各个兼容模式……