在C语言中模拟含有默认参数的函数
【好久没写了,来篇技术科普文】
写C++代码的时候总想当然以为C中也有含默认参数的函数这种玩意儿(值得注意的是Java也不支持而C#支持,Scala这种奇葩支持是不足为奇的),然后在编译下面这段代码之后颜面扫尽TwT
#include "default_args.h"
void printString(const char* msg,int size,int style){
printf("%s %d %d\n",msg,size,style);
}
int main(){
printString("hello");
printString("hello",12);
printString("hello",12,bold);
}
#include<stdio.h>
enum{
plain=0,italic=1,bold=2
};
void printString(const char* msg,int size=18,int style=italic);
nonoob@nonoobPC$ clang default_args.c -o default_args In file included from default_args.c:1: ./default_args.h:12:42: error: C does not support default arguments ...
clang果然是人性化的编译器,还会告诉我们真实的原因;不像gcc只会报出一堆慕名奇妙的error信息,读者不妨自己尝试一下,这里就不吐槽了。至于如果我们的目的在于只要编译通过的话,那完全可以无节操地把这段代码当成C++代码,然后用clang++或g++来搞定这一切;最多只是会报出一个warning(而如果把default_args.c换成default_args.cpp的话连clang++都不报任何警告):
clang: warning: treating 'c' input as 'c++' when in C++ mode, this behavior is deprecated
传说中程序员只关心error而不管warning,那大可就此打住并到stackoverflow的这个thread上灌水一番。不过如果是那种闲着无聊且非常执着的话(或者是那种没法用C++而只能选择C的情况,抑或是那种考虑到在其他C的源文件中用到printString()函数的情况),那不妨往下看。一个很容易想到的解决方案自然是重载函数了(先不管效率)。在default_args.c删掉函数中的默认值并添加下面这段:
void printString(const char *msg,int size){
printString(msg,size,italic);
}
但却是:
nonoob@nonoobPC$ clang override_args.c -o override_args override_args.c:14:6: error: conflicting types for 'printString'
又一次颜面扫尽,C原来连重载函数都不支持>_<,弱爆了。没辙了吗?就不能猥琐地模拟一下然后让C语言程序员也享受一下默认参数的快感吗?macro!C程序员的必杀技,一个被C++程序员吐槽无数的招数:-(,但却是一个很优雅的解决方案^_^
#include<stdio.h>
enum{
plain=0,italic=1,bold=2
};
void printString(const char* message, int size, int style) {
printf("%s %d %d\n",message,size,style);
}
#define PRINT_STRING_1_ARGS(message) printString(message, 18, italic)
#define PRINT_STRING_2_ARGS(message, size) printString(message, size, italic)
#define PRINT_STRING_3_ARGS(message, size, style) printString(message, size, style)
#define GET_4TH_ARG(arg1, arg2, arg3, arg4, ...) arg4
#define PRINT_STRING_MACRO_CHOOSER(...) \
GET_4TH_ARG(__VA_ARGS__, PRINT_STRING_3_ARGS, \
PRINT_STRING_2_ARGS, PRINT_STRING_1_ARGS, )
#define PRINT_STRING(...) PRINT_STRING_MACRO_CHOOSER(__VA_ARGS__)(__VA_ARGS__)
int main(int argc, char * const argv[]) {
PRINT_STRING("Hello, World!");
PRINT_STRING("Hello, World!", 12);
PRINT_STRING("Hello, World!", 12, bold);
return 0;
}
看到这么一坨代码,估计没几个人喜欢——宏这种对把源代码看成白盒的程序员实在不友好的东西,然而却让所有的C程序员大受其益。不妨看一下NULL的定义:
#define NULL ((void *)0)
闲话不扯了,看看前段代码是怎么回事;毕竟子曾曰过:举一隅不以三隅反,则不复也。
macro本身也不是什么见不得人的东西,说到底就是方便程序员偷懒的,在实现的最终目的上和函数没有本质区别。这里需要注意的是__VA_ARGS__这个东东。其洋名叫Variadic Macros,就是可变参数宏,在这里是配合“...”一起用的。可变参函数想必C程序员都不陌生,就是没吃过猪肉也见过猪跑是吧,比如printf;这里也有个tutorial。我们在这里需要知道的是宏定义(define)处的“...”是可以和宏使用(use)处的多个参数一起匹配的。下面以PRINT_STRING("Hello, World!", 18);为例说明是怎么展开的。
首先"Hello,World!", 12匹配PRINT_STRING_MACRO_CHOOSER(...)中的"...",于是被扩展成:
PRINT_STRING_MACRO_CHOOSER("Hello, World!", 12)("Hello, World!", 12);
而PRINT_STRING_MACRO_CHOOSER("Hello, World!",12)又被扩展成
GET_4TH_ARG("Hello, World!", 12, PRINT_STRING_3_ARGS, PRINT_STRING_2_ARGS, PRINT_STRING_1_ARGS, )
所以整条语句被扩展成了
GET_4TH_ARG("Hello, World!", 12, PRINT_STRING_3_ARGS, PRINT_STRING_2_ARGS, PRINT_STRING_1_ARGS, )("Hello, World!", 12);
接下来看到的是匹配#define GET_4TH_ARG(arg1,arg2,arg3,arg4, ...)arg4的情况,"Hello,World!"匹配args1,12匹配arg2,PRINT_STRING_3_ARGS匹配arg3,PRINT_STRING_2_ARGS匹配arg4,而其余, PRINT_STRING_1_ARGS, 的部分匹配了“...”,所以经过这一番扩展变成了
PRINT_STRING_2_ARGS("Hello, World!", 12);
即为
printString("Hello, World!", 12,1);
这样一番折腾终于见到庐山真面目了。当然我们可以用gnu cpp查看一下预处理的结果是不是这样的(一般来讲C和C++用preprocessor是一样的)。
...
int main(int argc, char * const argv[]) {
printString("Hello, World!", 18, italic);
printString("Hello, World!", 12, italic);
printString("Hello, World!", 12, bold);
return 0;
}
这也解释了为什么说用macro的解决方案是优雅的。不妨再看看生成的llvm的ir形式:
nonoob@nonoobPC$ clang macro.c -S -o - -emit-llvm
; ModuleID = 'macro.c'
target datalayout = "e-p:32:32:32-i1:8:8-i8:8:8-i16:16:16-i32:32:32-i64:32:64-f32:32:32-f64:32:64-v64:64:64-v128:128:128-a0:0:64-f80:32:32-n8:16:32-S128"
target triple = "i386-pc-linux-gnu"
@.str = private unnamed_addr constant [10 x i8] c"%s %d %d\0A\00", align 1
@.str1 = private unnamed_addr constant [14 x i8] c"Hello, World!\00", align 1
define void @printString(i8* %message, i32 %size, i32 %style) nounwind {
%1 = alloca i8*, align 4
%2 = alloca i32, align 4
%3 = alloca i32, align 4
store i8* %message, i8** %1, align 4
store i32 %size, i32* %2, align 4
store i32 %style, i32* %3, align 4
%4 = load i8** %1, align 4
%5 = load i32* %2, align 4
%6 = load i32* %3, align 4
%7 = call i32 (i8*, ...)* @printf(i8* getelementptr inbounds ([10 x i8]* @.str, i32 0, i32 0), i8* %4, i32 %5, i32 %6)
ret void
}
declare i32 @printf(i8*, ...)
define i32 @main(i32 %argc, i8** %argv) nounwind {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
%3 = alloca i8**, align 4
store i32 0, i32* %1
store i32 %argc, i32* %2, align 4
store i8** %argv, i8*** %3, align 4
call void @printString(i8* getelementptr inbounds ([14 x i8]* @.str1, i32 0, i32 0), i32 18, i32 1)
call void @printString(i8* getelementptr inbounds ([14 x i8]* @.str1, i32 0, i32 0), i32 12, i32 1)
call void @printString(i8* getelementptr inbounds ([14 x i8]* @.str1, i32 0, i32 0), i32 12, i32 2)
ret i32 0
}
很清爽的代码,令人心旷神怡吧。
废了这么大的力气才做了这么点事,还不如不用“默认参数”呢是吧?但是当把这个写成库的时候,或者以后要经常使用的话这就方便多了,且不容易出错!
为了无聊起见,再看看default_org.h+default_org.c用clang++/g++编译得到的llvm的ir:
nonoob@nonoobPC$ clang++ default_args.c -S -o - -emit-llvm
clang: warning: treating 'c' input as 'c++' when in C++ mode, this behavior is deprecated
; ModuleID = 'default_args.c'
target datalayout = "e-p:32:32:32-i1:8:8-i8:8:8-i16:16:16-i32:32:32-i64:32:64-f32:32:32-f64:32:64-v64:64:64-v128:128:128-a0:0:64-f80:32:32-n8:16:32-S128"
target triple = "i386-pc-linux-gnu"
@.str = private unnamed_addr constant [10 x i8] c"%s %d %d\0A\00", align 1
@.str1 = private unnamed_addr constant [6 x i8] c"hello\00", align 1
define void @_Z11printStringPKcii(i8* %msg, i32 %size, i32 %style) {
%1 = alloca i8*, align 4
%2 = alloca i32, align 4
%3 = alloca i32, align 4
store i8* %msg, i8** %1, align 4
store i32 %size, i32* %2, align 4
store i32 %style, i32* %3, align 4
%4 = load i8** %1, align 4
%5 = load i32* %2, align 4
%6 = load i32* %3, align 4
%7 = call i32 (i8*, ...)* @printf(i8* getelementptr inbounds ([10 x i8]* @.str, i32 0, i32 0), i8* %4, i32 %5, i32 %6)
ret void
}
declare i32 @printf(i8*, ...)
define i32 @main() {
%1 = alloca i32, align 4
store i32 0, i32* %1
call void @_Z11printStringPKcii(i8* getelementptr inbounds ([6 x i8]* @.str1, i32 0, i32 0), i32 18, i32 1)
call void @_Z11printStringPKcii(i8* getelementptr inbounds ([6 x i8]* @.str1, i32 0, i32 0), i32 12, i32 1)
call void @_Z11printStringPKcii(i8* getelementptr inbounds ([6 x i8]* @.str1, i32 0, i32 0), i32 12, i32 2)
%2 = load i32* %1
ret i32 %2
}
从这里的IR中我们至少可以得到两点信息:
- C++编译得到的函数名和C编译得到的不一样(事实上是很不一样,可以参见name mangling),使用c++filt之后我们可以看到C++中的printString的签名实际上是void @printString(char const*, int, int)(i8* %msg, i32 %size, i32 %style)而不再是void @printString(i8* %message, i32 %size, i32 %style)。同时这也解释了为何在C中不会有函数的(静态)重载(没有OO自然动态重载更无从说起)——假设C有函数重载的话,会生成三个同名的函数,而C中调用函数时仅仅根据符号表中的函数名,这样就会造成混乱。【TODO:动态重载实现机理】
- 编译得到的代码中是看不到任何默认构造函数的信息的(同样连enum的信息也没有了),3条call指令中我们得到的只不过是对应下面源代码的指令(也没有生成三个签名不同但名字相同的函数printString())。
printString("hello",18,1);
printString("hello",12,1);
printString("hello",12,2);
到此为止,正文结束。下面贴捣鼓的一段含宏的代码~~
#include<stdio.h>
#include<stdarg.h>
#define LOGSTRING(fm,...) printf(fm,__VA_ARGS__)
#define MY_DEBUG(format,...) fprintf(stderr,NEWLINE(format),##__VA_ARGS__);
#define NEWLINE(str) str "\n"
#define GCC_DBG(format,args...) fprintf(stderr,format,##args)
#define DEBUG(args) (printf("DEBUG: "), printf args)
#define STRING(str) #str
#define NULL 3
int main(int argc,char**argv){
LOGSTRING("Hello %s %s\n","Hong""xu","Chen");
MY_DEBUG("my debug")
GCC_DBG("gcc dbg\n");
int n = 0;
if (n != NULL) DEBUG(("n is %d\n", n));
puts(STRING(It really Compiles!));
return 0;
}
参考资料:
- http://stackoverflow.com/questions/3046889/optional-parameters-with-c-macros
- http://www.cnblogs.com/alexshi/archive/2012/03/09/2388453.html
编译原理学习笔记06_antlr初步
antlr是什么
权威解释见官方或wikipedia,我只负责八卦。作者Terence Parr似乎是个有洁癖的人,写了antlr第一个版本之后觉得效率不高又写了v2,因为同样的理由又推倒重来写了v3。尽管以java为主打,但这个antlr非常有野心,Java/C#/Python/Ruby/Scala等语言通吃;由grammar生成lexer和parser使得这玩意儿非常适合教学用,也非常适合菜鸟级程序员提高编写编译器的自信。虽说没有JavaCC这么正统,但是个人觉得非常实用,现在Hibernate framework/Jython/Groovy可都是基于antlr的哦!这哥们还开发了一套template engine,同样是一个妄图大一统文本解析的干活。有了antlr这把锤子他就开始到处乱敲:paper自不用说,然后是《The Definitive ANTLR Reference》、《Language Implementation Patterns》。后者近期被译成中文,号称“屠龙”;虽说的确过誉了,但是不得不承认这本书的确深入浅出。尽管作者一直在自卖自夸antlr和StringTemplate,但是对于java系的人来讲这的确是学习编译原理基础知识的好东西;连Guido大叔和Dalvik设计者Dan Bornstein也对这本书颇有好评。
安装工具
antlr:http://www.antlr.org/download.html
对于我这样的习惯了eclipse的懒人来说antlrworks并不是上上之策,插件才是王道http://antlrv3ide.sourceforge.net/。
该插件特点:
- 新建一般的java project(如果要生成的目标语言是java的话)并convert成antlr即可,之后只需写grammar文件。
- 默认情况下保存每一次grammar文件就会进行自动生成对应的lexer和parser的java文件(默认target language是java)和对应tokens文件;每次打开eclipse时会重新解析一次。
- 似乎生成的lexer和parser并不会添加grammar文件所在package信息(吐槽:这一点和上面一个特点加起来足以让人抓狂!!!)。
- 编辑器的content assit功能和java编辑器的功能有不少出入,括号、引号、缩进等功能做得并不好。
- grammar(g文件)除编辑器的两个tab Interpreter和Railroad view非常棒,一个用于傻瓜式写,一个用于GUI显示,并且可以导出成html。
还可以考虑使用StringTemplate:http://www.stringtemplate.org/download.html
开始使用
以含有加减乘法的计算器且目标语言java为例。
- 在g文件中写出所要定义的grammer(一般是词法和语法的综合)
grammar Expr;
prog : stat+;
stat : expr NEWLINE
| ID '=' expr NEWLINE
| NEWLINE
;
expr: multiExpr (('+'|'-') multiExpr)*
;
multiExpr : atom('*' atom)*
;
atom : INT
| ID
| '(' expr ')'
;
ID : ('a'..'z'|'A'..'Z')+ ;
INT : '0'..'9'+;
NEWLINE : '\r'?'\n';
WS : (' '|'\t'|'\n'|'\r')+{skip();};
- 生成的ExprLexer.java文件中会将'(',')'等涉及判定的字符用新的identifier如T__8等来对应,识别这样的字符的方法形如T__8。新生成的ExprLexer类继承了antlr定义的Lexer类,封装了一些方法。ExprParser继承Parser类,诸如expr等g文件中的左式会有个对应的方法(例如expr())来处理它;为了处理出错和从错误状态恢复,该类还生成了FOLLOW_expr_in_stat34这样的变量并调用了pushFollow()这类方法。
- 这样,从输入流中可以生成lexer对象,将由lexer得到的tokens作为输入就得到一个parser对象;调用顶层的方法就可以完成语法分析了。
public static void main(String[] args) throws IOException, RecognitionException {
// TODO Auto-generated method stub
ANTLRInputStream input = new ANTLRInputStream(System.in);
ExprLexer lexer = new ExprLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
ExprParser parser = new ExprParser(tokens);
parser.prog();
}
- 上述代码对于符合grammar的输入不会有输出,如果需要给出相应的输出的话仍可以在g文件中添加(java)代码。
- 添加包含的package
@header{
import java.util.HashMap;
}
- 添加parser中的成员变量
@members{
/** Map variable name to Integer object holding value */
HashMap memory = new HashMap();
}
- 添加parser中左式处理函数的返回值(前面代码中的方法的返回值都为void),并且在每个生成式上在{}里添加特定的方法。值得注意的是对于诸如INT这样在lexer中得到的Token用的是antlr定义好的Token类的一个对象,包含了getText()方法;故不需要定义INT的text返回值。如下面的一段:
expr returns [int value]
: e=multExpr {$value = $e.value;}
( '+' e=multExpr {$value+=$e.value;}
| '-' e=multExpr {$value-=$e.value;}
)*
;
multExpr returns [int value]
: e = atom {$value=$e.value;}('*' e=atom {$value *= $e.value;})*
atom returns [int value]
: // value of an INT is the int computed from char sequence
INT {$value=Integer.parseInt($INT.text);}
| ID // variable reference
{
// look up value of variable
Integer v = (Integer)memory.get($ID.text);
// if found, set return value else error
if(v!=null) $value = v.intValue();
else System.err.println("undefined variable "+$ID.text);
}
// value of parenthesized expression is just the expr value
| '(' expr ')'{$value=$expr.value;}
;
--------------------------------------------------
参考自《The Definitive ANTLR Reference》,又是一本没付版权费的电子书:(
PS:通过antlr生成的代码,我才知道java对于退出多重循环有个不错的做法,就是在指定的循环前面添加上某个label,然后在要退出的时候加上break label。我们都知道尽管java把goto作为保留字,但是在咱码农是没法用goto的。使用这样break的做法肯定没有C/C++来得凶残;但是无疑很好地避免了goto带来的无结构编程恶习,同时又保留了灵活性(似乎该对D.E.Knuth致敬?)。
编译原理学习笔记05_解析树和AST
参考自《Language Implementation Patterns》第4章。
----------------------------------------------
识别语句时,需要关心元素的顺序,同时也要考虑元素之间的关系(嵌套);用树状结构较好(同时可参考xml及lisp,话说含嵌套的list应该就可以理解为tree了吧);parse在进行自顶向下解析的时候一般是可以描绘出parse tree的(它恰好是parse的执行轨迹)。比如在解析x=0;时是通过这样的规则的:
statement:assignment
|...
;
assignment:ID '=' expr
|...
;
expr:...
;
用(已经简化了的)解析树表示就是:
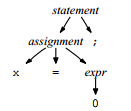
但是这其中涉及到的内部节点其实只在解析过程中有用,那些assignment这类的都只是中间表达形式,真正有用的是叶子节点(terminal);同时这样的树遍历起来也不方便。所以只要能解析(在这里就是抽象地表达赋值语句)并构建其他数据结构(可能下面的阶段会用到),用AST就行了。
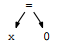
在AST中,操作符的优先级越高,位置越低;这和写规则的时候用到的中间变量的层次是一样的。比如含有+,-,*,/的单数字文法:
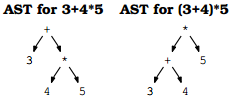
expr:expr+term|expr-term|term; term:term*factor|term/factor|factor; factor:digit|(expr); digit:[0-9];
前序表达式可以唯一确定树的形式,这可以作为树的文本表示形式(又是lisp)。
对于不含可执行语句的语句,可定义伪操作(如graphivz);对输入中没有作为root节点的token时可定义虚token(如c中的声明)。
理论上说AST节点其实只要一种数据结构就OK了,这样设计的AST结构成为同型AST。下面是java的一个实现。
public class AST {
Token token;
List<AST> children;
public AST(Token token) {
this.token = token;
}
public void addChild(AST t) {
if (children == null)
children = new ArrayList<AST>();
children.add(t);
}
...
}
这里用于区分不同类型语句的其实是靠token的类型来完成的,就像这样tree.token.getType()。这样的设计渣的地方显而易见。首先类型token的属性而不是节点的属性,带来的性能上的问题很大;很明显一般来说这样的代码是需要重构的。其次如果要添加额外信息的话不管三七二十一所有节点都得加上,代价太大。虽然simple&stupid,但对于OO思想占主流的时代这样的数据结构显然不能令人满意啊(这不gcc都用C++写了)。因此有了异型AST(又分为规范子节点和不规则子节点两种),以后详述。
编译原理学习笔记04_LL及谓词解析
从现在起正式把《编程语言设计模式》(中文版和英文电子版)加为参考书目。
-----------------------------------------------------
对于一个parser,规范的命名是LL(k),LR(k)之类。LL(k)的含义:第一个L只按从左到有顺序解析输入内容,第二个L表示自顶向下解析时按照从左到右顺序遍历子节点,k表示forward的token为k个。而LL(k)中的r表示的是自底向上解析时按照从右向左推导(从左向右规约)。
LL分析的时候先看到的是产生式左值,然后确定其是由什么右值构成的;于是要做的事就是迭代地匹配产生式,这涉及到了不断地猜测、回溯,通常将A的产生式分为first(A)和follow(A)(和lisp中的car/cdr看起来有些像哈>o<)。这里的“顶”应该是从语法树上看的。LR正好相反,是从产生式的右值开始分析的,开始拿到的是推导式右值中的一个文法(grammar)符号;也可以说是从语法树的叶子节点开始分析。
上下文无关文法(context free grammar)是指没有二义性的文法。一个具有二义性的语法可以参照C++:
T(a)
在只知道T和a是token的情况下,它可能指下面几种情况(或其中一部分):
- 函数声明,如int foo(int);
- 对象初始化,如Fraction f(42);
- 函数调用,如bar(-67);
- 强制类型转换,如float(11);
当然在C++手册中规定遇到这种情况声明(a)比表达式(b)(c)(d)优先级较高,所以在构造解析规则的时候通常隐含(用了if-else等分支结构)对解析选项进行了排序,例如:
stat:(declaration)=>declaration
|expression
;
也就是说只要看起来像声明了,就认为是声明;确定不是声明那种货色的了,才考虑它匹配表达式。但问题在于仍然没有办法区分(b)(c)(d)的情况。如果用LL(k)的话,因为在对象初始化前还有一个token(如Fraction),是可以区分(b)和(c)(d)。然而,仅凭这些还是无法区分(c)(d)。事实上这两者的CFG是一样的:
expr:INTEGER
|ID '(' expr ')'//bar(-67)
|ID '(' expr ')'//float(11);
;
这时就需要采用语义信息了,通常LL(k)是采用形如这样的谓词判断:
void expr() {
if ( LA(1)==INTEGER) match(INTEGER);
else if ( LA(1)==ID && isFunction(LT(1).text) ) «match-function-call »
else if ( LA(1)==ID && isType(LT(1).text) ) «match-typecast »
else «error »
}
在编写解析不同同种语言的解析器是也会用到谓词逻辑;比如gcc的那100+个坑爹的选项,比如java的各个兼容模式……
编译原理学习笔记03
在字符粒度上,语法(syntax)就是词法结构(lexical structure);用正则表达式可以搞定对词法的处理。
BNF是CFG的一种表示方法,有这样的形式:
symbol ::= __expression__
其中symbol(三角括号不是必须的)是nonterminal;__expression__是一个包含symbol的表达式,仅可以由“|”连接;尽在BNF的右边出现的symbol是terminal。即只要在左边出现过一次,任何一个symbol就失去了成为terminal的资格。反过来看,现实世界其实只有terminal出现,任何句子、词语最终都是terminal组成的;nonterminal都只是便于理解加的中间层。
ABNF仅在BNF上加了注释信息,换汤不换药:
rule ::= definition ; comment CR LF
EBNF是基于BNF的一种扩展,按照wiki的定义有这些记号:
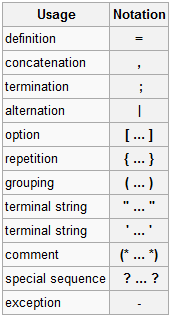
但是更多情况下涉及到的是下面的符号:
- (token) 打包成整体
- token? $\le 1$个token
- token* kleene start,$\ge 0$个token
- token+ kleene cross,$\ge 1$个token
- . 匹配任意一个token
- ~token 没有token(即“非”)
- a..z a到z间的所有字符
具体是什么好像没有绝对的说法,只是为了便于表达;ANTLR用的是后面的说法。
BNF和EBNF可以相互转化,既可以用于lexer规则也可用于parser规则(这也可以从CFG比regex牛逼看出,而regex完全可以搞定词法)。
lexer规则(BNF左边)要么是literal要么是是其他规则的引用;parser规则可以引用词法规则、语法规则,也可以包含literal。比如下面这个例子:
decl : 'int' ID '=' INT ';' // E.g., "int x = 3;"
| 'int' ID ';' // E.g., "int x;"
;
ID : ('a'..'z' | 'A'..'Z')+;
INT : '0'..'9'+;