编译原理学习笔记03
nonoob
posted @ Wed, 22 Aug 2012 21:18:43 +0800
in Programming
, 5795 readers
在字符粒度上,语法(syntax)就是词法结构(lexical structure);用正则表达式可以搞定对词法的处理。
BNF是CFG的一种表示方法,有这样的形式:
symbol ::= __expression__
其中symbol(三角括号不是必须的)是nonterminal;__expression__是一个包含symbol的表达式,仅可以由“|”连接;尽在BNF的右边出现的symbol是terminal。即只要在左边出现过一次,任何一个symbol就失去了成为terminal的资格。反过来看,现实世界其实只有terminal出现,任何句子、词语最终都是terminal组成的;nonterminal都只是便于理解加的中间层。
ABNF仅在BNF上加了注释信息,换汤不换药:
rule ::= definition ; comment CR LF
EBNF是基于BNF的一种扩展,按照wiki的定义有这些记号:
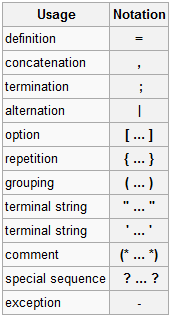
但是更多情况下涉及到的是下面的符号:
- (token) 打包成整体
- token? $\le 1$个token
- token* kleene start,$\ge 0$个token
- token+ kleene cross,$\ge 1$个token
- . 匹配任意一个token
- ~token 没有token(即“非”)
- a..z a到z间的所有字符
具体是什么好像没有绝对的说法,只是为了便于表达;ANTLR用的是后面的说法。
BNF和EBNF可以相互转化,既可以用于lexer规则也可用于parser规则(这也可以从CFG比regex牛逼看出,而regex完全可以搞定词法)。
lexer规则(BNF左边)要么是literal要么是是其他规则的引用;parser规则可以引用词法规则、语法规则,也可以包含literal。比如下面这个例子:
decl : 'int' ID '=' INT ';' // E.g., "int x = 3;"
| 'int' ID ';' // E.g., "int x;"
;
ID : ('a'..'z' | 'A'..'Z')+;
INT : '0'..'9'+;
Wed, 03 Jan 2024 01:39:28 +0800
I'm curious if anyone has had success with aftermarket upgrades to reinforce slots. เว็บตรง แตกง่าย
Thu, 04 Jan 2024 14:23:55 +0800
Your collection of the biggest web slots is a testament to your commitment to gaming excellence. สล็อตเว็บใหญ่ที่สุด
Mon, 15 Jan 2024 14:19:26 +0800
This is exceptionally fascinating, yet it is important to tap on this connection: สล็อตรวมทุกค่าย
Tue, 16 Jan 2024 19:27:39 +0800
So it is intriguing and great composed and see what they think about other individuals. Pokdeng
Wed, 17 Jan 2024 01:36:40 +0800
Mmm.. great to be here in your article or post, whatever, I figure I ought to likewise buckle down for my own site like I see some great and refreshed working in your site. สล็อตโรม่า
Fri, 02 Feb 2024 17:52:35 +0800
This substance is just energizing and innovative. I have been settling on an institutional move and this has helped me with one angle. concierge doctor