编译原理学习笔记05_解析树和AST
参考自《Language Implementation Patterns》第4章。
----------------------------------------------
识别语句时,需要关心元素的顺序,同时也要考虑元素之间的关系(嵌套);用树状结构较好(同时可参考xml及lisp,话说含嵌套的list应该就可以理解为tree了吧);parse在进行自顶向下解析的时候一般是可以描绘出parse tree的(它恰好是parse的执行轨迹)。比如在解析x=0;时是通过这样的规则的:
statement:assignment
|...
;
assignment:ID '=' expr
|...
;
expr:...
;
用(已经简化了的)解析树表示就是:
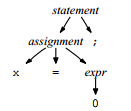
但是这其中涉及到的内部节点其实只在解析过程中有用,那些assignment这类的都只是中间表达形式,真正有用的是叶子节点(terminal);同时这样的树遍历起来也不方便。所以只要能解析(在这里就是抽象地表达赋值语句)并构建其他数据结构(可能下面的阶段会用到),用AST就行了。
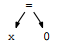
在AST中,操作符的优先级越高,位置越低;这和写规则的时候用到的中间变量的层次是一样的。比如含有+,-,*,/的单数字文法:
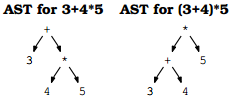
expr:expr+term|expr-term|term; term:term*factor|term/factor|factor; factor:digit|(expr); digit:[0-9];
前序表达式可以唯一确定树的形式,这可以作为树的文本表示形式(又是lisp)。
对于不含可执行语句的语句,可定义伪操作(如graphivz);对输入中没有作为root节点的token时可定义虚token(如c中的声明)。
理论上说AST节点其实只要一种数据结构就OK了,这样设计的AST结构成为同型AST。下面是java的一个实现。
public class AST {
Token token;
List<AST> children;
public AST(Token token) {
this.token = token;
}
public void addChild(AST t) {
if (children == null)
children = new ArrayList<AST>();
children.add(t);
}
...
}
这里用于区分不同类型语句的其实是靠token的类型来完成的,就像这样tree.token.getType()。这样的设计渣的地方显而易见。首先类型token的属性而不是节点的属性,带来的性能上的问题很大;很明显一般来说这样的代码是需要重构的。其次如果要添加额外信息的话不管三七二十一所有节点都得加上,代价太大。虽然simple&stupid,但对于OO思想占主流的时代这样的数据结构显然不能令人满意啊(这不gcc都用C++写了)。因此有了异型AST(又分为规范子节点和不规则子节点两种),以后详述。
Mon, 01 Jan 2024 01:50:51 +0800
Good site! I really love how it is easy on my eyes it is. I am wondering how I could be notified whenever a new post has been made. I have subscribed to your feed which may do the trick? Have a nice day! DESALINATION PLANT MANUFACTURER
Wed, 03 Jan 2024 00:02:46 +0800
Can I just now say such a relief to get somebody who really knows what theyre discussing on-line. You definitely learn how to bring a difficulty to light and produce it critical. The diet really need to read this and appreciate this side from the story. I cant think youre no more well-known simply because you undoubtedly provide the gift. Horseback riding Smoky Mountains
====================
Thank you for your wonderful post! It has long been very insightful. I hope that you’ll continue sharing your wisdom with us. black soap
====================
I am typically to blogging i truly appreciate your articles. This great article has truly peaks my interest. Let me bookmark your internet site and maintain checking for brand new info. Knoxville web design
====================
You ought to be a part of a contest for just one of the finest blogs on the web. I am going to suggest this site! swimming pool contractors in Pigeon Forge
Wed, 03 Jan 2024 01:38:13 +0800
I wonder if there's a correlation between the price of slots and their durability. เว็บตรง แตกง่าย
Thu, 04 Jan 2024 14:23:00 +0800
Your passion for the biggest web slots shines through. What a fantastic resource. สล็อตเว็บใหญ่ที่สุด
Tue, 09 Jan 2024 05:28:00 +0800
This site is really a walk-through for all of the information you wanted about it and didn’t know who to question. Glimpse here, and you’ll certainly discover it. fisio
=========================
Thus you wish efficient online income ideas for keep present in setting aside time for tips appropriate for very own web-based marketing. Inernet marketing casa de cambio
Tue, 09 Jan 2024 17:33:05 +0800
Thank you for the sensible critique. Me & my friend were just preparing to do a little research about this. We got a book from our local library but I think I learned more from this post. I’m very glad to see such magnificent info being shared freely out there. bigfatcc
===========================
Very nice post. I just stumbled upon your blog and wanted to say that I have really enjoyed surfing around your blog posts. In any case I will be subscribing to your feed and I hope you write again soon! permis de construire architecte
Mon, 15 Jan 2024 14:18:24 +0800
Astounding, this is awesome as you need to take in more, I welcome to This is my page. รวมสล็อตทุกค่ายในเว็บเดียว
Tue, 16 Jan 2024 18:11:41 +0800
Intriguing and fascinating data can be found on this theme here profile worth to see it. เกมไพ่ป๊อกเด้ง
Wed, 17 Jan 2024 01:28:57 +0800
Incredible tips and straightforward. This will be exceptionally helpful for me when I get an opportunity to begin my blog. เกมสล็อตโรม่า
Fri, 19 Jan 2024 00:24:58 +0800
Its excellent as your other content : D, thanks for putting up. PFAS CONTAMINATED WATER TREATMENT TECHNIQUES to remove per- and poly-fluoroalkyl compounds (PFAS)
Fri, 19 Jan 2024 00:25:17 +0800
Greetings, May I grab your page picture and implement it on my own blog page? danceable Arabic music
Mon, 22 Jan 2024 21:34:44 +0800
You have some honest ideas here. I done a research on the issue and discovered most peoples will agree with your blog. After that early period, the Beatles evolved considerably over the years. Rappelz private server
=======================
Awesome! I thank you your blog post to this matter. It has been useful. Media files
Fri, 26 Jan 2024 01:00:04 +0800
Discover the intricate art of Aari embroidery at Chennai Fashion Institute. Our Aari embroidery classes provide a comprehensive learning experience, combining traditional techniques with modern trends. Unleash your creativity and master the skill of Aari embroidery under the guidance of expert instructors. Join us to add a touch of elegance to your creations. Aari embroidery classes
Tue, 30 Jan 2024 00:18:27 +0800
I stumbled upon Timely Magazine News while searching for a reliable source of up-to-the-minute information, and I must say, it has become my go-to platform for staying informed. The commitment to delivering timely and relevant news is evident in every aspect of this magazine. The range of topics covered is impressive, catering to a diverse audience with varied interests.timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews timelymagazinenews
Tue, 30 Jan 2024 00:38:05 +0800
Don't let large images compromise your website's performance—resize them! resize
Wed, 31 Jan 2024 03:10:24 +0800
Ha ha… I was just browsing around and took a glance at these responses. I can’t believe there’s still this much attention. Thanks for posting about this. car tyres Birmingham
======================
I discovered your blog website on google and verify a couple of of your early posts. Proceed to maintain up the superb operate. I just further up your RSS feed to my MSN Information Reader. Seeking forward to reading extra from you in a while!… coffee
======================
Thank you for the sensible critique. Me & my friend were just preparing to do a little research about this. We got a book from our area library but I think I learned better from this post. I am very glad to see such wonderful info being shared freely out there… hotels
=======================
An fascinating discussion may be worth comment. I do think that you need to write regarding this topic, it might become a taboo subject but typically individuals are not enough to communicate in on such topics. To a higher. Cheers car events
Fri, 02 Feb 2024 20:02:59 +0800
Benefit as much as possible from primarily premium substances - you will discover him or her for: concierge doctor
Fri, 02 Feb 2024 22:24:34 +0800
Bhutan, often referred to as the "Land of the Thunder Dragon," exudes a palpable aura of tranquility and spirituality. Spiritual Immersion in Bhutan
Sun, 04 Feb 2024 22:11:26 +0800
The Cornell method encourages you to scrutinize source material, dissect it, and ask relevant questions. By paraphrasing and rewriting notes, you improve your critical thinking skills, learn how to express your thoughts, and separate useful knowledge from the noise. AI Workflow Techniques
Fri, 09 Feb 2024 18:12:05 +0800
It’s difficult to acquire knowledgeable individuals for this topic, nevertheless, you sound like you know what you are discussing! Thanks Centro de Emprego Online
=================
Comfortabl y, the post is really the freshest on this deserving topic. I harmonise with your conclusions and definitely will thirstily look forward to your next updates. Just saying thanks definitely will not simply just be adequate, for the extraordinary clarity in your writing. I can directly grab your rss feed to stay informed of any updates. Gratifying work and also much success in your business dealings! masaje erotico palma
==================
marketing online is of course a good business and also a great way to earn money online“ empresa de control de plagas en Madrid
==================
Sometimes your blog is loading slowly, better find a better host. reparation pc boulogne billancourt
Sat, 10 Feb 2024 18:02:51 +0800
The Evolution of SEO Consultancy in the digital age, where online visibility can make or break a business, mastering the art of search engine optimization (SEO) has become paramount. Affordable SEO Manchester
Tue, 13 Feb 2024 17:18:19 +0800
Considerably, the article is in reality the greatest on that noteworthy topic. I agree with your conclusions and can eagerly look forward to your next updates. Saying thanks will not simply just be enough, for the excellent clarity in your writing. I definitely will promptly grab your rss feed to stay privy of any updates. Pleasant work and also much success in your business dealings! Thermador refrigerator repair
=========================
Do you accept guest posts? I would like to write couple articles here. locksmith
Sun, 25 Feb 2024 22:48:59 +0800
I’m curious to find out what blog system you’re using? I’m experiencing some minor security issues with my latest blog and I’d like to find something more risk-free. Do you have any suggestions? Nieuws Vandaag
==========================
A very informationrmative post and lots of really honest and forthright comments made! This certainly got me thinking about this issue, cheers all. Tech Nieuws
Fri, 08 Mar 2024 05:26:20 +0800
I’m impressed, I have to admit. Actually rarely must i encounter a weblog that’s both educative and entertaining, and without a doubt, you’ve got hit the nail on the head. Your notion is outstanding; the pain is something which too little people are speaking intelligently about. I am happy i came across this in my search for something about it. AMIClubwear
======================
Great site. Plenty of useful information here. I’m sending it to a few friends ans also sharing in delicious. And certainly, thanks for your sweat! carte uno reverse
Sat, 09 Mar 2024 05:48:56 +0800
Youre so cool! I dont suppose Ive read anything like that before. So nice to seek out somebody by incorporating original applying for grants this subject. realy we appreciate you beginning this up. this site is something that is required over the internet, somebody after a little originality. useful project for bringing interesting things for the world wide web! Cuevana
========================
Its not that I need to duplicate your web website, but I truly like the formatof your site. Could you let me know which theme are you using? Or was it custom made? Loja Cidadão
Wed, 13 Mar 2024 17:53:21 +0800 Spot lets start on this write-up, I truly feel this website needs a lot more consideration. I’ll apt to be again to learn to read additional, thank you that information. Sensors
Sat, 30 Mar 2024 00:03:39 +0800
Basically to follow up on the up-date of this matter on your web site and would really want to let you know how much I appreciated the time you took to put together this valuable post. In the post, you actually spoke on how to definitely handle this challenge with all ease. It would be my pleasure to get some more strategies from your blog and come up to offer people what I discovered from you. I appreciate your usual good effort. Psychedelische relatietherapie
=================================
Et bien oui et surtout pas vraiment. Ouais étant donné que il se peut qu’on détermine d’autres causes qui certainement citent d’identiques significations. Non car cela n’est pas assez de transcrire ce que tout le monde être autorisé à rencontrer chez certains pages tiers et de le traduire tellement naturellement? https://www.panttaegi82.com/safefesta
Sun, 07 Apr 2024 04:27:57 +0800
That first offered me personally about this point of view to cope with something which gives a crucial description improving ? Kitchen installations kent
=================
Howdy! Someone in my Myspace group shared this site with us so I came to take a look. I’m definitely loving the information. I’m book-marking and will be tweeting this to my followers! Superb blog and great style and design. origin data
=================
Can I simply say what a relief to search out somebody who truly is aware of what theyre speaking about on the internet. You undoubtedly know the way to convey a difficulty to light and make it important. More individuals must read this and understand this facet of the story. I cant consider youre no more common since you definitely have the gift. Isolators Suppliers
=================
This web-site may be a walk-through like the info you wished about it and didn’t know who ought to. Glimpse here, and you’ll undoubtedly discover it. Connectors Suppliers
=================
What are you stating, man? I recognize everyones got their own opinion, but really? Listen, your website is awesome. I like the work you put into it, especially with the vids and the pics. But, come on. Theres gotta be a better way to say this, a way that doesnt make it seem like everybody here is stupid! Discrete Semiconductor Products Suppliers
=================
there are textured table linens which are much better than untextured table linena;; Integrated Circuits Suppliers
=================
One thing I would like to say is that car insurance canceling is a feared experience so if you’re doing the suitable things as being a driver you won’t get one. A number of people do receive the notice that they’ve been officially dropped by their insurance company they then have to struggle to get supplemental insurance after a cancellation. Cheap auto insurance rates usually are hard to get from cancellation. Knowing the main reasons for auto insurance canceling can help people prevent getting rid of in one of the most essential privileges readily available. Thanks for the ideas shared through your blog. 智勤芯科技
Wed, 10 Apr 2024 01:58:32 +0800
Attractive element of content. I just stumbled upon your weblog and in accession capital to say that I get in fact enjoyed account your blog posts. Anyway I will be subscribing on your augment or even I fulfillment you access persistently rapidly. rolling serving cart
===================
Oh my goodness! an incredible article dude. Thank you Nonetheless I am experiencing problem with ur rss . Don know why Unable to subscribe to it. Is there anybody getting an identical rss drawback? Anybody who is aware of kindly respond. Thnkx laundry sorter 2 section
Thu, 11 Apr 2024 23:37:15 +0800
Thanks for making the trustworthy attempt to discuss this. I believe very strong approximately it and would like to learn more. If it’s OK, as you achieve extra extensive knowledge, may you mind including more articles very similar to this one with more information? It might be extraordinarily helpful and helpful for me and my friends. Hoteis no Centro do Porto
=====================
Excellent website right here! Additionally your website starts up very fast! What host are you using? Can you pass along your affiliate hyperlink to your host? I desire my site loaded up as quickly as yours lol rtp jokerwin77
=====================
Hola i would really love to subscribe and read your blog posts ; Spinbettter Registration
Sun, 14 Apr 2024 18:52:08 +0800
I’ve also been meditating on the identical idea personally lately. Happy to see somebody on the same wavelength! Nice article. how can a beginner make money online
Tue, 16 Apr 2024 00:04:55 +0800
I hope your knowledge gets spread around so a lot of people can see what the real problems are in this situation. casino
======================
I do not even know how I ended up here, but I thought this post was good. I don’t know who you are but definitely you’re going to a famous blogger if you aren’t already Cheers! sabong bet
Fri, 19 Apr 2024 20:52:22 +0800
Thanks for the blog loaded with so many information. Stopping by your blog helped me to get what I was looking for. Premium service
Wed, 24 Apr 2024 17:50:14 +0800
Thanks for sharing superb informations. Your web site is so cool. I’m impressed by the details that you have on this website. It reveals how nicely you understand this subject. Bookmarked this website page, will come back for extra articles. You, my pal, ROCK! I found simply the information I already searched all over the place and just couldn’t come across. What a great web site. <a href="https://maxim-88.com/">Maxim88 Casino</a>
Wed, 24 Apr 2024 17:50:47 +0800
After study a number of the websites on your internet site now, and i genuinely like your way of blogging. I bookmarked it to my bookmark web site list and are checking back soon. Pls have a look at my web page likewise and make me aware if you agree. Maxim88 Casino
Fri, 03 May 2024 20:05:48 +0800 Awesome article! I want people to know just how good this information is in your article. It’s interesting, compelling content. Your views are much like my own concerning this subject. grinder
Sun, 05 May 2024 04:04:11 +0800
Hey man, .This was an excellent page for such a hard subject to talk about. I look forward to reading many more great posts like these. Thanks fp a distancia
================
Some really quality blog posts on this site, saved to fav. Disney Lorcana
================
Woh Everyone loves you , bookmarked ! My partner and i take issue in your last point. Receitas de Bacalhau
Sun, 05 May 2024 23:26:28 +0800
Aw, it was a very good post. In idea I would like to devote writing such as this furthermore,?¡ìC spending time and specific work to produce a great article?- nonetheless so what can I say?- I waste time alot and never at all seem to obtain one thing completed. Buy Tramadol Powder China
=================
Super-Duper website! I am loving it!! Will be back later to read some more. I am bookmarking your feeds also Get OriginalPrometric exam (DHA, MOH) Exam Question and Answer
==================\
I have been meaning to read this and just never obtained a chance. It’s an issue that I’m really interested in, I just started reading and I’m glad I did. You’re a fantastic blogger, one of the best that I’ve seen. This weblog undoubtedly has some facts on topic that I just wasn’t aware of. Thanks for bringing this stuff to light. BUY FRCOG DEGREE WITHOUT EXAM
Thu, 09 May 2024 12:54:43 +0800 Wow i can say that this is another great article as expected of this blog.Bookmarked this site.. AI images
Fri, 10 May 2024 20:50:20 +0800
This is really interesting, I’ll check out your other posts! https://mana.pro/funny-good-morning-images/
===============
I believe you have remarked some very interesting details , thankyou for the post. playstation 5 с два джойстика
===============
I think other site proprietors should take this website as an model – very clean and magnificent style and design, as well as the content. You are an expert in this area! Кулинария
===============
Just what I was looking for, appreciate it for posting . cube blog
Wed, 15 May 2024 02:59:56 +0800
thank for sharing this with all of us. Of course, what a great site and informationrmative posts, I will bookmark this site. keep doing your great job and always gain my support. cheers for sharing this beautiful story Affordable and Reliable
Sun, 19 May 2024 17:16:56 +0800
It’s difficult to acquire knowledgeable folks with this topic, nevertheless, you seem like there’s more you are referring to! Thanks Best Crypto Exchange in Dubai
Mon, 20 May 2024 04:22:12 +0800
Bloghopping is really my forte and i like to visit blogs” luxury car rental Dubai
===========================
Hello i would really love to subscribe and read your blog posts .! Crypto buy signal for 100X
Fri, 24 May 2024 15:34:53 +0800 I think one of your ads caused my internet browser to resize, you may well want to put that on your blacklist. LAUNCH YOUR OWN CRYPTO COIN WITHOUT LIQUIDITY
Fri, 24 May 2024 15:35:28 +0800
The when I read a weblog, I really hope so it doesnt disappoint me about that one. Get real, I know it was my substitute for read, but When i thought youd have something fascinating to say. All I hear is really a handful of whining about something that you could fix should you werent too busy searching for attention. thiên đường trò chơi
Sat, 25 May 2024 21:37:57 +0800
Hey, Great website basically a heads up that I was getting instantly sent straight to the homepage if I viewed this internal web page; It looked like a web browser hi-jack or something, I’m not too absolutely certain but imagined you might be informed about it. Take care BECOME OWNER OF YOUR MEMECOIN AND START EARNING IN ETH
======================
i found your blog through a search engine, very interesting. Puffin Internet Browser
Thu, 30 May 2024 02:56:32 +0800
Youre so cool! I dont suppose Ive read anything similar to this before. So nice to discover somebody with original ideas on this subject. realy thanks for starting this up. this web site is a thing that is required on the net, somebody if we do originality. beneficial job for bringing something new to the internet! credit card debt
Fri, 31 May 2024 02:21:10 +0800
I saw a lot of website but I believe this one contains something extra in it in it Industrial battery chargers
Sat, 01 Jun 2024 21:22:41 +0800
Some really fantastic information, Sword lily I detected this. save and share deals
Sun, 02 Jun 2024 13:53:30 +0800
Hmm is anyone else encountering problems with the pictures on this blog loading? I’m trying to figure out if its a problem on my end or if it’s the blog. Any suggestions would be greatly appreciated. gut riechen
Sun, 02 Jun 2024 19:05:19 +0800
Please let me know if you’re looking for a author for your site. You have some really good posts and I believe I would be a good asset. If you ever want to take some of the load off, I’d really like to write some content for your blog in exchange for a link back to mine. Please blast mean e-mail if interested. Regards! BOTTLING PLANT MANUFACTURER
Tue, 04 Jun 2024 14:34:50 +0800
I discovered your blog site on bing and check a few of your early posts. Always keep up the excellent operate. I just now additional your Feed to my MSN News Reader. Seeking toward reading much more on your part at a later time!… web hosting service
Tue, 04 Jun 2024 21:44:06 +0800
I believe this is one of the most significant information for me. And i am satisfied studying your article. But wanna commentary on some basic things, The web site taste is wonderful, the articles is in point of fact excellent . Good activity, cheers. Dubai gold jewelery
=================
Je pourrais vous en transférer les adresses pour plus de picto en relation avec cette question. Ecrivez moi par mail. Curiosidades
================
What a great post. Thank you very much for sharing those knowledge. I will of course check it out. enjoy olimpia park resort
Wed, 05 Jun 2024 21:57:19 +0800
This is actually attractive, You’re particularly expert article author. I have signed up with your feed and additionally expect enjoying all of your really good write-ups. At the same time, I’ve shared the blog throughout our social networking sites. architectural design
===============
Can I just say what a reduction to find someone who truly is aware of what theyre talking about on the internet. You definitely know tips on how to convey a problem to light and make it important. More individuals have to read this and perceive this side of the story. I cant consider youre not more common because you positively have the gift. WATER BOTTLING PLANT MANUFACTURER
Thu, 06 Jun 2024 21:24:10 +0800
Many thanks for making the effort to discuss this, I feel strongly about this and like learning a great deal more on this matter. If feasible, as you gain knowledge, would you mind updating your webpage with a great deal more info? It’s really helpful for me. crypto development company
Sun, 09 Jun 2024 15:23:09 +0800
There are some interesting points with time in this article but I do not know if I see every one of them center to heart. There is some validity but I most certainly will take hold opinion until I check into it further. Very good post , thanks and now we want a lot more! Included with FeedBurner as well BOTTLING PLANT MANUFACTURER FOR ENERGY DRINK PLANTS
===============
Wow! This could be one particular of the most helpful blogs We’ve ever arrive across on this subject. Basically Wonderful. I’m also an expert in this topic so I can understand your effort. Sexólogo
===============
Hey there. I discovered your website by way of Google even as searching for a similar matter, your web site came up. It seems to be great. I have bookmarked it in my google bookmarks to come back later. Clases de Danza Contemporanea Granada
Tue, 11 Jun 2024 13:28:21 +0800
This would be the proper weblog for anybody who really wants to find out about this topic. You recognize a lot its practically tricky to argue along (not that I actually would want…HaHa). You certainly put a whole new spin with a topic thats been revealed for some time. Fantastic stuff, just excellent! https://namesflare.com/
================
I am usually to blogging i truly appreciate your site content. Your content has truly peaks my interest. Let me bookmark your web blog and keep checking choosing information. surgical tech certification programs
================
After research a few of the blog posts in your website now, and I really like your method of blogging. I bookmarked it to my bookmark website listing and will probably be checking again soon. Pls check out my web page as nicely and let me know what you think. how to find the best price for a house rental in Montreal?
Wed, 12 Jun 2024 02:02:11 +0800
I have to say i am very impressed with the way you efficiently site and your posts are so informative. You have really have managed to catch the attention of many it seems, keep it up! najlepszy osrodek terapii
================
An fascinating discussion may be worth comment. I think that you should write regarding this topic, it will not often be a taboo subject but generally persons are inadequate to talk on such topics. To another. Cheers fast track surgical tech programs
Wed, 19 Jun 2024 03:54:58 +0800
Dude.. I am not much into reading, but somehow I got to read plenty of articles on your blog. Its amazing how interesting it is for me to check out you incredibly often. this site
===============
Hello! I just now wish to provide a huge thumbs up for the great information you could have here during this post. We are coming back to your website for further soon. visit post
===============
After study a handful of the blog posts in your site now, we truly appreciate your method of blogging. I bookmarked it to my bookmark website list and will also be checking back soon. Pls take a look at my site also and tell me how you feel. visit article
================
There is noticeably big money to know about this. I assume you made specific nice points in functions also. read more
Thu, 20 Jun 2024 04:47:34 +0800
We provide commercial and residential real estate photography / videography in North Carolina. Services for Airbnb's and short term rental properties as well as Multi-family homes and new construction. We also offer aerial services, 3D tour, and Floor plans. https://g.page/r/Cdm9Zo0QBAvPEBM/review photographers in greensboro nc
Thu, 20 Jun 2024 20:43:27 +0800
Get the best pressure washing service in Stow, Ohio, without breaking the bank! Our affordable rates and sparkling results will leave you impressed. https://g.co/kgs/kuu6s4h Gutter Cleaning Service in Stow
====================
One thing is that if you find yourself searching for a student loan you may find that you’ll want a co-signer. There are many circumstances where this is correct because you will find that you do not use a past history of credit so the mortgage lender will require that you’ve got someone cosign the borrowed funds for you. Good post. senyumslot
Fri, 21 Jun 2024 20:02:28 +0800
I am not sure where you are getting your information, but good topic. I needs to spend some time learning much more or understanding more. Thanks for wonderful information I was looking for this info for my mission. recliner chair
=================
I like this website so much, bookmarked . qué es VPN
=================
Was required to give you that not much remark to appreciate it just as before for these spectacular techniques you’ve got provided on this page. It’s so particularly generous with normal folks that you to provide unreservedly what many people would have marketed as a possible e-book to earn some dough for their own end, primarily considering that you may have tried it if you wanted. The tactics also acted being fantastic way to know that everyone’s similar desire equally as my to understand significantly more regarding this condition. I’m sure there are many more pleasing opportunities at the start if you go through your blog post post. Facial In Redondo Beach, CA Facial In Redondo Beach, CA
Mon, 24 Jun 2024 03:32:31 +0800
dog crates made from ABS Plastic can withstand those aggressive dogs; Mississauga Pest Control
Fri, 28 Jun 2024 23:29:15 +0800
Well, the article is actually the sweetest on this notable topic. I harmonise with your conclusions and will certainly thirstily look forward to your next updates. Saying thanks can not simply just be sufficient, for the extraordinary lucidity in your writing. I will directly grab your rss feed to stay abreast of any kind of updates. Solid work and much success in your business efforts! GEL batteries
================
Props for these a good post, maintain up your fantastic function. cannabis near me
================
I’d should consult with you here. Which isn’t some thing I do! I quite like reading a post that can make people think. Also, appreciate your allowing me to comment! Digital Girlfriend
Mon, 01 Jul 2024 19:22:56 +0800
This is very educational content and written well for a change. It's nice to see that some people still understand how to write a quality post! Reparar MacBook
==============
I would like to say that this blog really convinced me to do it! Thanks, very good post. Pump Repair
Wed, 03 Jul 2024 23:59:09 +0800
howdy, I’m havin a tough time trying to rank up for the keyword “victorias secret coupon codes”… Pls approve my comment!! Aladin138
Wed, 10 Jul 2024 16:09:30 +0800
Spot i’ll carry on with this write-up, I actually think this site needs considerably more consideration. I’ll more likely be once more to see a great deal more, thanks for that information. Pivotal Practices consulting
===============
I discovered your blog web site on google and test a few of your early posts. Continue to keep up the superb operate. I simply extra up your RSS feed to my MSN News Reader. In search of forward to studying extra from you afterward!… Illinois Roofing School
===============
There is apparently a bunch to identify about this. I believe you made various good points in features also. Heavy-duty furniture hardware
Thu, 11 Jul 2024 02:49:41 +0800
Some genuinely nice and utilitarian info on this internet site , too I think the layout holds fantastic features. ARSENIC REMOVAL PLANT MANUFACTURER
==================
I definitely wanted to post a simple remark in order to thank you for all the unique tips and tricks you are giving out on this website. My incredibly long internet search has finally been recognized with extremely good points to go over with my company. I ‘d say that we readers are very blessed to exist in a superb site with so many awesome people with good advice. I feel pretty happy to have come across your entire website and look forward to tons of more brilliant moments reading here. Thanks a lot once more for everything. tokyo revengers live action
Mon, 15 Jul 2024 17:33:21 +0800
Youre so cool! I dont suppose Ive learn anything like this before. So good to seek out any person with some authentic thoughts on this subject. realy thanks for beginning this up. this web site is one thing that’s wanted on the internet, somebody with slightly originality. helpful job for bringing something new to the web! Ablegrid smart scale
====================
We happen to be truly satisfied in which Raymond can deal with his research via the tips he or she received with all the web site. It’s now and once again puzzling to simply be offering information that numerous another folks have recently been selling. We realize we have the writer by way of thanking because of this. The sort of drawings you have made, the straightforward internet site navigation, the relationships a person help to engender ?ê? it’s every thing amazing, and it’s also producing the boy as well as us all think that the topic is actually pleasant, and that’s amazingly obligatory. We appreciate you almost all! Buy Original ECFMG Certificate Without Exam
Tue, 16 Jul 2024 20:54:30 +0800
thank you for sharing – Gulvafslibning | Kurt Gulvmand with us, I conceive – Gulvafslibning | Kurt Gulvmand genuinely stands out : D. Coeur d’Alene Wedding Photographers
==============
I have learn some just right stuff here. Certainly value bookmarking for revisiting. I wonder how a lot effort you put to make this sort of fantastic informative site. Wedding Videographers Galveston, TX
Thu, 25 Jul 2024 23:59:31 +0800
You made some decent points there. I appeared on the internet for the difficulty and found most individuals will go along with with your website. Office Headshot Photographers
=================
A few things i have constantly told people is that when searching for a good on-line electronics retail outlet, there are a few variables that you have to remember to consider. First and foremost, you need to make sure to choose a reputable as well as reliable retail store that has got great opinions and scores from other shoppers and business world professionals. This will make sure that you are getting along with a well-known store that can offer good assistance and assistance to their patrons. Thank you for sharing your notions on this weblog. Real Estate Agent Headshot photographers Miami, FL
=================
Exactly where maybe you have discovered the source meant for the following write-up? Great reading through I’ve subscribed to your blog feed. Marrietta Newborn Photographers
=================
Some genuinely nice and utilitarian information on this web site, also I conceive the layout has got superb features. automation in marketing
Sat, 27 Jul 2024 17:54:47 +0800
Have you ever heard of a decent design?? This one sucks man. The articles are great tho’. Metal Recovery from Tailings, Mining Dam, Mining Pit, Tailing Storage Facility
========================
i would love to see a massive price drop on internet phones coz i like to buy lots of em, Vacation
Mon, 29 Jul 2024 15:25:11 +0800
Both Allen and Terry idolize the superstar macho detectives (played with comic relish by Samuel L. oversized recliner
Mon, 29 Jul 2024 15:25:50 +0800
What refreshing delight your posts are. I understood this should be here yet I ultimately became fortunate and the search terms worked. Getting more people to be part of the discussion is actually a positive thing. recliner chair
Tue, 30 Jul 2024 03:41:13 +0800
I was looking through some of your content on this internet site and I conceive this site is rattling informative ! Continue putting up. Regalos Personalizados
================
The when I read a blog, I hope that this doesnt disappoint me as much as this place. I am talking about, It was my solution to read, but I actually thought youd have something intriguing to mention. All I hear is a few whining about something that you could fix in case you werent too busy looking for attention. Yoga
Thu, 01 Aug 2024 02:33:50 +0800
information you write it very clean. I’m very lucky to get this information from you.|very good information you write it very clean. I’m very lucky to get MINING DAM, TAILING STORAGE FACILITY HEAVY METAL REMOVAL, WASTEWATER TREATMENT PLANT MANUFACTURER
=========================
Youre so cool! I dont suppose Ive read anything in this way just before. So nice to find somebody with original thoughts on this subject. realy thank you for starting this up. this website are some things that is required on the net, an individual after a little originality. useful work for bringing a new challenge towards world wide web! Online reservation
Thu, 01 Aug 2024 16:56:59 +0800
Well We certainly loved studying this. This topic acquired using a person is quite effective for accurate planning. 新作AV動画
Sat, 03 Aug 2024 00:40:06 +0800 Wow, this is really interesting reading. I am glad I found this and got to read it. Great job on this content. I like it. Painting Company San Diego
Wed, 07 Aug 2024 21:06:35 +0800
Hey. Neat post. There is a problem with your site in firefox, and you may want to check this… The browser is the market chief and a large component of other folks will omit your excellent writing because of this problem. REVERSE OSMOSIS PLANT FOR MINING INDUSTRY
Mon, 12 Aug 2024 17:54:43 +0800
When I originally commented I clicked the -Notify me when new surveys are added- checkbox and from now on whenever a comment is added I purchase four emails sticking with the same comment. Perhaps there is by any means you may get rid of me from that service? Thanks! 素人エロ動画
===============
An incredibly fascinating read, I might not concur completely, but you do make some extremely valid points. 工務店のWEB集客
===============
I simply could not go away your site prior to suggesting that I actually enjoyed the standard information an individual supply to your visitors? Is gonna be again continuously in order to check out new posts 翔べるエロ動画
===============
There is noticeably a bundle to learn about this. I assume you made specific nice points in features also. 東京都の漢方薬局
Thu, 22 Aug 2024 15:34:29 +0800
Discover the convenience of purchasing Sugar Defender through Amazon.
This comprehensive guide explores the benefits of Sugar Defender, a natural supplement designed to support healthy blood sugar levels, enhance energy, and contribute to overall wellness.
Learn why Amazon is your go-to source for Sugar Defender.
Thu, 22 Aug 2024 15:35:29 +0800
Discover the convenience of purchasing Sugar Defender through Amazon.
This comprehensive guide explores the benefits of Sugar Defender, a natural supplement designed to support healthy blood sugar levels, enhance energy, and contribute to overall wellness.
Learn why Amazon is your go-to source for Sugar Defender.
Thu, 22 Aug 2024 15:36:13 +0800
Discover the convenience of purchasing Sugar Defender through Amazon.
This comprehensive guide explores the benefits of Sugar Defender, a natural supplement designed to support healthy blood sugar levels, enhance energy, and contribute to overall wellness.
Learn why Amazon is your go-to source for Sugar Defender.
Thu, 05 Sep 2024 02:21:26 +0800
I have to convey my respect for your kindness for all those that require guidance on this one field. Your special commitment to passing the solution up and down has been incredibly functional and has continually empowered most people just like me to achieve their dreams. Your amazing insightful information entails much to me and especially to my peers. Thanks a ton; from all of us. ラッコキーワードの有料版
================
You completed a number of nice points there. I did a search on the issue and found nearly all people will have the same opinion with your blog. 地域集客(田舎集客)
================
I would like to convey my admiration for your generosity in support of men and women that have the need for help with this particular concern. Your special dedication to getting the message all over had been wonderfully productive and have all the time made professionals much like me to attain their dreams. Your own invaluable tutorial means a great deal to me and additionally to my office workers. Thank you; from everyone of us. キーワードプランナーの代わり
================
This is getting a bit more subjective, but I much prefer the Zune Marketplace. The interface is colorful, has more flair, and some cool features like ‘Mixview’ that let you quickly see related albums, songs, or other users related to what you’re listening to. Clicking on one of those will center on that item, and another set of “neighbors” will come into view, allowing you to navigate around exploring by similar artists, songs, or users. Speaking of users, the Zune “Social” is also great fun, letting you find others with shared tastes and becoming friends with them. You then can listen to a playlist created based on an amalgamation of what all your friends are listening to, which is also enjoyable. Those concerned with privacy will be relieved to know you can prevent the public from seeing your personal listening habits if you so choose. スレンダーなのにデカ尻AV女優
===================
Needed to compose you a tiny note to finally thank you very much yet again for your personal splendid methods you have discussed above. It is strangely open-handed with people like you to provide publicly all that a number of people would have marketed as an electronic book to generate some bucks for their own end, primarily now that you could possibly have tried it if you ever wanted. These inspiring ideas likewise acted like a fantastic way to know that the rest have the same dreams really like my personal own to see a whole lot more concerning this problem. I’m sure there are thousands of more enjoyable times in the future for many who check out your blog. レセプト
===================
Interesting website, i read it but i still have a few questions. shoot me an email and we will talk more becasue i may have an interesting idea for you. https://chinsuji.com/
===================
Your article has proven useful to me. It’s very informative and you are obviously very knowledgeable in this area. You have opened my eyes to varying views on this topic with interesting and solid content. エロ同人
===================
I must say, as a lot as I enjoyed reading what you had to say, I couldnt help but lose interest after a while. Its as if you had a wonderful grasp on the subject matter, but you forgot to include your readers. Perhaps you should think about this from far more than one angle. Or maybe you shouldnt generalise so considerably. Its better if you think about what others may have to say instead of just going for a gut reaction to the subject. Think about adjusting your own believed process and giving others who may read this the benefit of the doubt. 口内発射
Fri, 06 Sep 2024 19:25:07 +0800
I really got into this article. I found it to be interesting and loaded with unique points of interest. I like to read material that makes me think. Thank you for writing this great content. ウェディングドレス レンタル
Just wanna remark on few general things, The website style is ideal, the topic matter is rattling good 素人女子のアダルト動画
I simply must tell you that you have written an excellent and unique article that I really enjoyed reading. I’m fascinated by how well you laid out your material and presented your views. Thank you. 自由が丘 痩身
Hi there, I found your website via Google while searching for a related topic, your website came up, it looks great. I have bookmarked it in my google bookmarks. 自由が丘 ダイエット
I really like your article. It’s evident that you have a lot knowledge on this topic. Your points are well made and relatable. Thanks for writing engaging and interesting material. 自由が丘 痩身
Mon, 09 Sep 2024 23:44:13 +0800
I am really inspired with your writing talent well with the layout to your weblog. Is this a paid topic or did you modify it your self? Anyway stay up the excellent high quality writing, it’s rare to peer a great blog like this one nowadays. 【ログイン】
Mon, 09 Sep 2024 23:44:31 +0800
It can be tough to write about this topic. I think you did an excellent job though! Thanks for this! 【ログイン】
Mon, 09 Sep 2024 23:44:59 +0800
It has always been my belief that good writing like this takes research and talent. It’s very apparent you have done your homework. Great job! 【ログイン】
Mon, 09 Sep 2024 23:48:34 +0800
Thank you that is very helpful for me, as a new site has been inundated with comments that seem OK at first glance but then get repeated with a slight change of wording. I have something concrete to go on now and will delete quite a lot of them. 宝塚市 外壁塗装
Sat, 14 Sep 2024 22:08:52 +0800
For my part, the particular was presented an employment which is non secular enlargement. 同人エロ漫画館
Sat, 14 Sep 2024 22:45:39 +0800
Thank you a bunch for sharing this with all of us you really recognise what you’re speaking about! Bookmarked. Kindly additionally consult with my site =). We may have a link exchange contract among us! 電子書籍
Sun, 22 Sep 2024 17:05:43 +0800
It is actually a nice and helpful piece of information. I am happy that you just shared this useful information with us. Please keep us up to date like this. Thanks for sharing. rentacarkosovo Japanese Pokemon Card
Sun, 22 Sep 2024 17:05:59 +0800
I’ve viewed some different blog posts with regards to this topic, and I must state that yours shows the most insight. Thanks a lot for expressing your opinions with everyone here. Japanese Pokemon Card
Sun, 22 Sep 2024 17:06:16 +0800
Your blog is amazing dude. i love to visit it everyday. very nice layout and content , Japanese Pokemon Card
Sun, 22 Sep 2024 17:07:17 +0800
I Just stopped by to say your article is great. The clarity in your post is simply spectacular and i can assume you’re an expert on this subject. Fine with your permission let me to grab your RSS feed to keep up to date with forthcoming post. Thanks a million and please continue the enjoyable work. おすすめの探偵
Sun, 22 Sep 2024 17:07:32 +0800
I was passing around and come across your site. It is wonderful. I mean as a content and design. I added you to my list and decided to spent the rest of the weekend browsing. Well done! 画力が高い・絵が上手いエロマンガ
Fri, 27 Sep 2024 23:21:03 +0800
you have a very fantastic weblog here! do you need to earn some invite posts on my small blog? 初めてでもわかる会社設立のすべて
Sat, 28 Sep 2024 03:03:25 +0800
There are definitely a variety of details like that to take into consideration. That is a great point to carry up. I offer the ideas above as normal inspiration however clearly there are questions just like the one you convey up where crucial thing will be working in sincere good faith. I don?t know if best practices have emerged around things like that, however I am certain that your job is clearly recognized as a fair game. Both boys and girls really feel the impact of just a second’s pleasure, for the rest of their lives. Electronics Parts Supply
Sat, 28 Sep 2024 03:04:38 +0800
You’ll find some intriguing points in time in this post but I do not know if I see all of them center to heart. There is certainly some validity but I will take hold opinion until I look into it further. Excellent post , thanks and we want more! Added to FeedBurner too Electronic Components Distributor
Sat, 28 Sep 2024 03:05:08 +0800
You can definitely see your skills within the work you write. The arena hopes for more passionate writers like you who are not afraid to say how they believe. All the time follow your heart. Origin Data Electronics
Tue, 08 Oct 2024 04:06:30 +0800
I’ve learned new things out of your blog post. One other thing I have observed is that in many instances, FSBO sellers will reject people. Remember, they might prefer not to use your companies. But if anyone maintain a reliable, professional connection, offering help and being in contact for about four to five weeks, you will usually manage to win a conversation. From there, a listing follows. Thanks a lot JRC Advisors
=================
Can I recently say thats a relief to locate someone who in fact knows what theyre preaching about on-line. You actually realize how to bring a challenge to light making it critical. More people should check out this and see why side of the story. I cant believe youre no more well-known simply because you definitely possess the gift. 女子高生レイプエロ動画
=================
I’m not sure exactly how I discovered your blog because I had been researching information on Real Estate in Altamonte Springs, FL, but anyway, I have had a pleasant time reading it, keep it up! 探偵や浮気調査のことなら探偵おすすめ比較Proへ
=================
Spot on with this write-up, I honestly think this excellent website wants a lot more consideration. I’ll more likely be again to see much more, thank you for that info. 探偵や浮気調査のことなら探偵おすすめ比較Proへ
Thu, 10 Oct 2024 03:59:08 +0800
I think this is among the most significant information for me. And i am glad reading your article. But want to remark on some general things, The web site style is perfect, the articles is really nice : D. Good job, cheers seo
Fri, 11 Oct 2024 03:27:10 +0800
Thank you for all of the efforts on this web site. My daughter really loves managing research and it’s really easy to see why. I notice all of the powerful form you offer useful secrets on your web site and as well attract contribution from website visitors on this theme plus our own child is truly being taught a great deal. Take advantage of the rest of the new year. You are always conducting a wonderful job. 巨乳AV女優の新着作品
You made some decent points there. I looked on the net for that issue and found most people will go coupled with with your internet site. M字開脚縛り
thanks for sharing your thoughts, I haven’t think of this before, keep posting mate! 財布の中古はやめたほうがいい
Sat, 12 Oct 2024 19:34:51 +0800
This is a great blog and i want to visit this every day of the week . 同人エロ漫画館
Mon, 14 Oct 2024 00:36:19 +0800
Exactly what you’re just saying entirely authentic. Actually , i know in which will have to the same, however , I simply think you put it in a fashion that everybody is able to comprehend. Also i like the images you spend at this point. They can fit consequently perfectly with what you are telling. Instant messaging certainly you may get to many people in what you have need to say. 無修正エロ動画
Tue, 15 Oct 2024 16:51:47 +0800 It’s perfect time to make some plans for the future and it is time to be happy. I have read this post and if I could I want to suggest you some interesting things or suggestions. Maybe you could write next articles referring to this article. I want to read more things about it! 漢方薬局
Wed, 16 Oct 2024 20:32:36 +0800
Great website. Plenty of helpful information here. I am sending it to some buddies ans additionally sharing in delicious. And certainly, thanks in your effort! FANZA MANIA
Wed, 16 Oct 2024 20:34:15 +0800
This looks absolutely perfect. All these tinny details are made with lot of background knowledge. I like it a lot. This was a useful post and I think it is rather easy to see from the other comments as well that this post is well written and useful. 事例制作
Wed, 16 Oct 2024 20:34:49 +0800
I hate my boss. So during the spare times, I am quite down and dumbed from the repetitive tasks. Your posts give my brain some needed excercise. Thanks! 東京の除霊
========================
I’ve recently started a site, the information you offer on this website has helped me greatly. Thanks for all of your time & work. 大阪の除霊
Mon, 21 Oct 2024 01:57:40 +0800
Greetings, have you ever before wondered to write regarding Nintendo Dsi handheld? 地酒OEM
Mon, 21 Oct 2024 01:58:30 +0800
As for Morgan Freeman, he was hardly there in the film. ギンギンブログ
Wed, 23 Oct 2024 16:09:04 +0800
You made some decent points there. I regarded on the internet for the difficulty and found most individuals will associate with with your website. 上尾 整体
Thu, 31 Oct 2024 00:18:03 +0800
After study a handful of the blog posts in your site now, we truly appreciate your method of blogging. I bookmarked it to my bookmark website list and will also be checking back soon. Pls take a look at my site also and tell me how you feel. Japanese Pokemon Card
There is noticeably big money to know about this. I assume you made specific nice points in functions also. 君にバナナ
Have you tried twitterfeed on your blog, i think it would be cool. 独占視聴スタイル
It’s perfect time to make some plans for the future and it’s time to be happy. I’ve read this post and if I could I want to suggest you some interesting things or suggestions. Perhaps you can write next articles referring to this article. I wish to read more things about it! MIZUNOBLOG
You can increase your blog visitors by having a fan page on facebook… わくわくびより
This is so good to see. We have do more things like this for other families. They are protecting us and we need to support them in this way. Japanese Pokemon Card
This web site is really a walk-through you discover the knowledge it suited you about this and didn’t know who to inquire about. Glimpse here, and you’ll undoubtedly discover it. エンタメ空間
Can I say thats a relief to discover a person that actually knows what theyre discussing on the web. You definitely have learned to bring a problem to light and earn it important. More and more people need to look at this and appreciate this side of the story. I cant believe youre less common as you definitely contain the gift. sensual-partners(エロ動画まとめサイト)
When I originally commented I clicked the -Notify me when new surveys are added- checkbox and today whenever a comment is added I receive four emails using the same comment. Perhaps there is any way you may remove me from that service? Thanks! 熟女エロ動画
There is noticeably a lot of money to know about this. I suppose you made particular nice points in functions also. 乱視用カラコン
Pretty nice post. I just stumbled upon your blog and wished to say that I’ve truly enjoyed browsing your blog posts. After all I will be subscribing to your feed and I hope you write again soon! Japanese Pokemon Card
Sat, 02 Nov 2024 19:36:53 +0800
Well done! I thank you your contribution to this matter. It has been insightful. my blog: how to get rid of love handles 素人エロ動画
Sat, 02 Nov 2024 23:16:43 +0800
you have a wonderful weblog here! want to develop invite posts in my weblog? 自宅英会話
Sat, 02 Nov 2024 23:51:41 +0800
well, i bought some digital pedometer on the local walmart and it is great for monitoring your performance when walking:: 抜けるエロ動画レビューブログ
Wed, 06 Nov 2024 03:34:16 +0800
An fascinating discussion will probably be worth comment. I do think that you can write regarding this topic, it will not become a taboo subject but typically everyone is too little to communicate in on such topics. Yet another. Cheers 英会話プライベートレッスン
Sun, 10 Nov 2024 19:06:54 +0800
AAAA
Sun, 10 Nov 2024 19:31:09 +0800
Thanks for sharing this! I learned a lot, and your perspective is refreshing. Twitter
Sun, 10 Nov 2024 19:44:12 +0800
This was an insightful read! I appreciate the time and effort you put into covering this topic. Hello
Sun, 10 Nov 2024 19:57:15 +0800
I love the way you explained everything so clearly. Keep up the awesome work! Hi
Sun, 10 Nov 2024 20:16:14 +0800
Great points! I hadn’t thought about it that way before – thanks for expanding my perspective. Hi
Sun, 10 Nov 2024 20:39:30 +0800
I found this post very helpful. The tips you shared are so practical and easy to apply. Hi
Sun, 10 Nov 2024 21:50:39 +0800
Really enjoyed this! Your writing style makes even complex topics easy to understand. Hi
Mon, 11 Nov 2024 19:04:58 +0800
Thank you for addressing this topic – it’s exactly what I was looking for! Hi
Mon, 11 Nov 2024 19:30:49 +0800
I always look forward to your posts. You have a way of making things interesting and relatable. Example
Sat, 16 Nov 2024 19:33:32 +0800
This was an amazing read! You’ve inspired me to learn more about this topic. Google
Sat, 16 Nov 2024 20:08:23 +0800
I really appreciate the depth of knowledge you bring to your posts. So helpful! Facebook
Sat, 16 Nov 2024 20:32:18 +0800
Such a fantastic post! Can’t wait to read more from you. Twitter
Sun, 17 Nov 2024 19:32:19 +0800
This was incredibly helpful. I’m definitely going to share this with others. Instagram
Sun, 17 Nov 2024 19:53:49 +0800
So many great ideas here, I’m excited to try them out! Twitch
Mon, 18 Nov 2024 19:06:34 +0800
I love how you explain things with such clarity. Great job! Blogger
Mon, 18 Nov 2024 19:49:44 +0800
Your posts always leave me inspired. Can’t wait for the next one! Tumblr
Mon, 18 Nov 2024 20:27:46 +0800
This is exactly the type of content I’ve been looking for. Great work! ChatGPT
Tue, 19 Nov 2024 19:30:29 +0800
I love how you included examples—it makes everything easier to understand! Claude
Tue, 19 Nov 2024 20:06:50 +0800
This is such a well-thought-out post. Thanks for sharing your knowledge. YouTube
Tue, 19 Nov 2024 22:37:10 +0800
hi!,I really like your writing so much! share we be in contact more approximately your article on AOL? I require a specialist in this space to resolve my problem. Maybe that is you! Having a look ahead to peer you. 【試し読み】
I think other web site proprietors should take this web site as an model, very clean and wonderful user genial style and design, let alone the content. You 英会話 家庭教師
thank you for such a fantastic site. Where else could anyone get that kind of information written in such a perfect way? I have a presentation that I am presently working on, and I have been on the look out for such information. スレンダー美女エロ動画
Thank you a lot for sharing this with all of us you really understand what you are talking approximately! Bookmarked. Please additionally visit my website =). We will have a hyperlink trade arrangement among us! 【試し読み】
Im no pro, but I believe you just crafted an excellent point. You clearly know what youre talking about, and I can really get behind that. Thanks for being so upfront and so sincere. マキマ 時間停止
Dude.. I am not much into reading, but somehow I got to read many articles on your blog. Its amazing how interesting it is for me to stop by you pretty often. ヒロインズ エロ
Can I just say what a reduction to find somebody who really is aware of what theyre speaking about on the internet. You undoubtedly know learn how to bring a problem to gentle and make it important. More people have to learn this and perceive this aspect of the story. I cant believe youre not more in style since you positively have the gift. 【試し読み】
Thu, 21 Nov 2024 01:56:32 +0800
Terrific story! Prefer appreciated a checking. I’m hoping for reading a great deal more from your business. I’m sure that you’ve good perception and additionally sight. My corporation is tremendously influenced due to this critical information. 【フル視聴】
Fri, 22 Nov 2024 00:01:41 +0800
Fantastic post – We subscribed to your main Feed. I prefer this you could have printed : lumber beneficial details. Getting lived in the for nearly Six to eight years now, That i never knew you can search criminal records internet, certainly arrest stats. It is really good toward understand – unfortunately chilling simultaneously! 【動画ダウンロード】