编译原理学习笔记02
nonoob
posted @ Tue, 03 Jul 2012 23:49:38 +0800
in Programming
, 2194 readers
-
CFG(contex free grammer而非control flow graph)比regex牛逼些:regex能生成的language是CFG能生成的language的(真)子集。NFA向CFG的规约可以按照下面的步骤:
- 为每个NFA中的状态$i$生成一个nonterminal $A_i$
- 若对于输入$i$有从$i$到$j$的状态转移,添加production $A_i\rightarrow aA_j$(若$a=\varepsilon$则添加production $A_i\rightarrow A_j$)
- 若$i$为初始态,令$A_i$为grammer的start symbol;若$i$为终态添加$A_i\rightarrow\varepsilon$
- regex(或FA)不能表达全部CFG能够表达的语法(“有限状态机不会数数”)。比如$L= \{a^nb^n|n\ge1\}$,可以用反证法证明它不能用有限状态机表述。
- 解释性语言天生就比编译型语言跨平台;它们至多只需要有统一的解释器罢了。Java就是这样一个另类(半编译半解释),而且还假装把这个解释器用的虚拟机做得像真的机器似的。所以虚拟化很重要啊,当解决不了问题或解决问题的方法不够妥当时,考虑加一个中间层的确有帮助。
- derivation和parser tree之间存在$1\rightarrow n$的关系,因为derivation是整个过程而parser tree是最终的结果而已;不过如果限定某种派生的准则(如leftmost/rightmost)两者就一一对应了。下面是两种不同的派生:
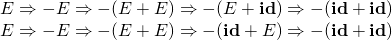
- parser tree是具体的语法树,其内部节点必然是非终结的(nonterminal,表示规则名),关注的是树节点的类型;syntax tree又称抽象语法树(AST),其内部节点仅仅表示程序结构。($S_{nonterminal}\varsubsetneqq S_{programming constructs}$)。parser tree比较严格,比如9-5+2中的9一定得画成像$number\rightarrow 9$这样的形式。大多数情况下,parse tree不如AST合适,但parser容易自动生成parse tree。
- JavaCC是词法分析器和语法生成器,用的是top-down的方式生成LL(k)语法,所以left recursive不能用。Lex是词法扫描器,Yacc是语法分析的,bottom-up。其中概念较多,以后单独对这部分内容作笔记。
Sat, 09 Apr 2022 18:53:42 +0800
Thank you for the update, very nice site.. 온라인바카라
Wed, 11 May 2022 18:32:43 +0800
The color of your blog is quite great. i would love to have those colors too on my blog.*’.*’ How to Start a Merchant Service Business
=======================================
After study a few of the blog posts on the site now, i genuinely like your way of blogging. I bookmarked it to my bookmark site list and are checking back soon. Pls take a look at my site in addition and make me aware what you think. Start a Credit Card Processing Company